Testing the Noise (Part 4)
Posted by Mark on September 13, 2019 at 06:16 | Last modified: June 10, 2020 11:36I am now ready (see here and here) to present detailed results of the Noise Test validation analysis.
The strategy counts by market are as follows:

DV #1 (original equity curve positioning within the simulated distribution) breaks down as follows:
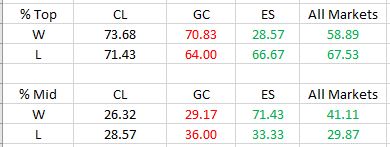
Frequencies are virtually identical for CL regardless of group (winning or losing strategies). Differences are seen for GC and ES with green and red indicating a difference as predicted or contrary to prediction, respectively. The more simulated curves that print above the original backtest, the more encouraged I should be that the strategy is not overfit to noise (see third graph here for illustration of the opposite extreme).
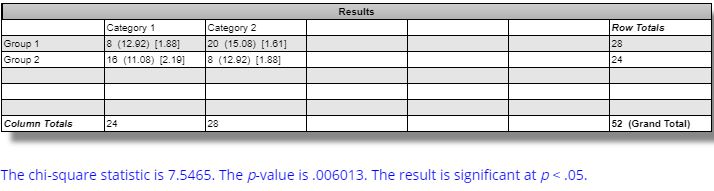
The difference in winning and losing strategies for ES is statistically significant per this website:
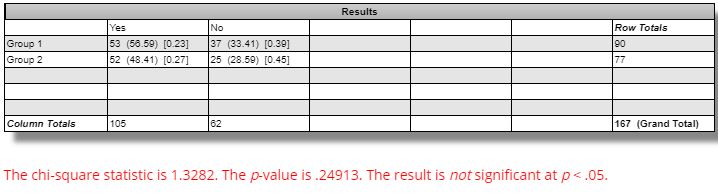
The difference between winning and losing strategies across all markets is not statistically significant:
DV #2 (percentages of strategies with all equity curves finishing breakeven or better) breaks down as follows:

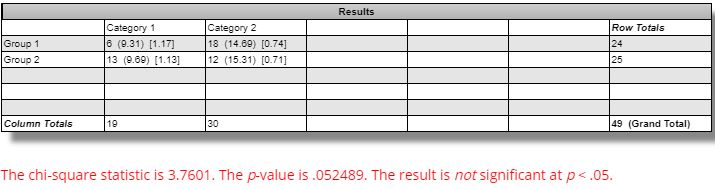
The difference seen between winning versus losing GC strategies is marginally significant (questionable relevance and even less so, in my opinion, due to smaller sample size):
The difference seen between winning versus losing ES strategies is not statistically significant:
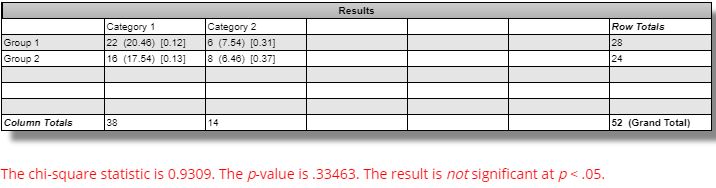
DV #3 (average Net Profit range as a percentage of original equity) breaks down as follows:

We should expect the simulated equity curves to be less susceptible to noise and therefore lower in range for the winning versus losing strategies. Across all markets, this difference is not statistically significant [(one-tailed) p ~ 0.15]. The difference for GC is statistically significant [t(49) = 2.92, (one-tailed) p ~ 0.003]: in the opposite direction from that expected.
Based on all these results, I do not believe the Noise Test is validated. The reason to stress potential strategies is because of a positive correlation with future profitability. I built 167 random strategies that backtested best of the best and worst of the worst. Unfortunately, I found little difference across my three validation metrics between extreme winners and extreme losers. My ideal hope would have been 12 significant differences in the expected directions. I may have settled for a few less. I got two with only one in the predicted direction.
Perhaps I could at least use Noise Test DV #1 on ES. I might feel comfortable with that if it were not for DV #3 on GC—equally significant, opposite direction—and an overall tally that suggests little more than randomness.
One limitation with this analysis is a potential confounding variable in the number of occurrences of open, high, low, and close (OHLC) in the [two] trading rules. My gut tells me that I should expect number of OHLC occurrences to be proportional to DV #3. A strategy without OHLC in the trading rules should present as a single line (DV #3 = 0%) on the Noise Test because nothing would change as OHLCs are varied. I am uncertain as to how X different OHLCs across the two rules should compare to just one OHLC appearing X times in terms of Noise Test dispersion.
I cannot eliminate this potential confound. However, this would not affect DV #1 and would perhaps only affect DV #2 to a small extent. More importantly, the strategies were built from random signals, which gives me little reason to suspect any significant difference between groups with regard to OHLC occurrences.
Categories: System Development | Comments (0) | PermalinkTesting the Noise (Part 3)
Posted by Mark on September 10, 2019 at 06:10 | Last modified: June 10, 2020 07:05Today I want to go through the Noise Test validation study, which I described in Part 2.
As I was reviewing screenshots for data evaluation, a few things came to light.
The consistency criterion (second-to-last paragraph of Part 2) is not an issue. All 167 strategies were “consistent” according to the Noise Test. When I decided to monitor this, I now wonder if I was remembering back to the Monte Carlo test instead.
Instead of consistency, I realized on some occasions all of the simulated curves were above zero. This percentage became dependent variable (DV) #2 and implies profitability regardless of noise. DV #1 describes where [Top, Mid(dle), or Bot(tom)] the original backtest terminal value falls within the equity curve distribution. DV #3 is net income range as a percentage of terminal net income for the original backtest.
I never saw the original backtest fall in the bottom third of the equity curve distributions (Bot, DV #1). This would be a most encouraging result that the software developers never presented as an example (see Part 1). Thanks for not deceiving us!
I found myself making some repetitive comments as I scored the data. On 19 occasions, I noted the original equity curve to be at the border of the upper and middle third of the distribution. Since equity values were estimated (platform does not have crosshairs or a data window), I simply alternated scoring Top and Mid whenever this occurred. I did not wish to feign more accuracy than the methods provide.
Also taking place on 19 occasions was a single simulated equity curve (out of 101) finishing below zero. One makes a big difference since the criterion is binary: all curves either avoid negative territory or they do not. This occurred 10 times for CL (split evenly between winning/losing groups), four times for GC (split evenly between winning/losing groups), and five times for ES (four winning and one losing strategy).
I recorded one CL strategy with an extremely profitable outlier and one GC and ES strategy, each, with an extremely unprofitable outlier.
I will present and discuss detailed results next time.
Categories: System Development | Comments (0) | PermalinkTesting the Noise (Part 2)
Posted by Mark on September 5, 2019 at 07:21 | Last modified: June 14, 2020 14:01Many unprofitable trading ideas sound great in theory. I want to feel confident the Noise Test isn’t one of them.
One big problem I see with the system development platform discussed last time is a lack of norms. In psychology:
> A test norm is a set of scalar data describing the performance
> of a large number of people on that test. Test norms can be
> represented by means and standard deviations.
The lack of a large sample size was part of my challenge discussed in Part 1. The software developers were kind enough to offer a few basic examples. The samples are singular and context is incomplete around each. I need to validate the Noise Test in order to know whether it should be part of my system development process. Without doing this, I run the risk of falling for something that sounds good in theory but completely fails to deliver.
I will begin by using the software to build trading strategies. I will study long/short equities, energies, and metals. I will look for the top and bottom 5-10 in out-of-sample (OOS) performance for each with OOS data selected as beginning and end (doubling sample size and re-randomizing trade signals to get different rules). I will then look at the Noise Test results over the IS period. If the Noise Test has merit, then results should be significantly better for the winners than for the losers.
I will score the Noise Test based on three criteria. First, I can approximate profitability range as a percentage of original net profit. This is understated because the Net Profit scale differs by graph based on maximum value (i.e. always pay attention to the max/min and y-axis tick values!). Second, I can determine whether the original equity curve falls in the middle, near the top, or near the bottom of the total [simulation] sample. For simplicity, I will just eye the range and divide it into thirds.
The final criterion will be consistency. In stress testing different strategies, I noticed these Top/Mid/Bot categories sometimes change from the left to the right edge of the performance graph. Is an example where the original backtest lags for much of the time interval and rallies into the finish really justified in being scored as “Top?” Had the strategy been assessed a few trades earlier, it would have scored as Mid thereby looking better in Noise Test terms (i.e. simulated outperformance relative to actual). Maybe I include only those strategies that score Yes for consistency.
I will continue next time.
Categories: System Development | Comments (0) | PermalinkTesting the Noise (Part 1)
Posted by Mark on August 30, 2019 at 07:41 | Last modified: June 9, 2020 15:23A lot of ideas sound really good but don’t play out as we might theoretically expect. This recurring theme applies to many disciplines but is particularly important in finance where the direct consequence is making money (e.g. second paragraphs here and here). Today, I want to focus this consideration on the Noise Test.
The Noise Test may be implemented as part of the trading system development process. The idea is that most overfit strategies are fit to noise (see second paragraph here). In order to screen for this, change the noise and retest the strategy. If the strategy still performs well then we can be more confident it is fit to actual signal.
One system development platform offers a Noise Test that works in the following way. For any underlying price series, a user-defined percentage of opens, highs, lows, and closes are varied up to another user-defined percentage maximum. The prices are recomputed some user-defined number of times and the strategy is re-run on these simulated price series. Original backtested performance is overlaid on the simulated performance. If the strategy is fit to noise then performance will degrade.
The software developers offer some examples as part of the training videos. This is supposedly a good result:
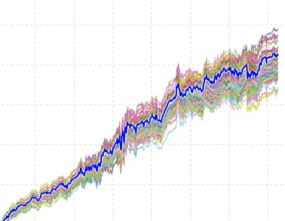
Note how concentrated the simulated equity curves are around the original backtest (bold blue line). Note also how the original backtest is centered within the simulated equity curves. In theory, both bode well for future performance.
Here is another good result:
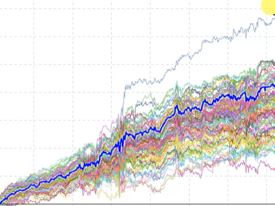
The simulated curves are more spread out, which translates to less confidence the strategy is actually fit to signal rather than overfit to noise. However, the outlier with windfall profits (on top) suggests a possibility that modulating noise can actually result in significantly better performance. The developers say this is a win and therefore a good result for the Noise Test.
Statistically speaking, I challenge this for two reasons. First, we have no idea whether this strategy is profitable going forward. Second, without a larger sample size I don’t know what to think about the profitable outlier. The Noise Test may be run on 10,000 different strategies without ever seeing this again. I can never draw meaningful conclusions from pure randomness.
The developers deem this a poor result of the Noise Test:
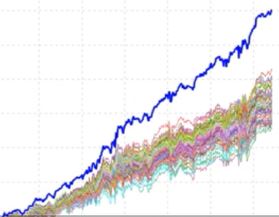
All simulated equity curves fare much worse than the original backtest, which suggests the original performance was fluke.
I will continue next time.
Categories: System Development | Comments (0) | PermalinkShort Premium Research Dissection (Part 41)
Posted by Mark on July 11, 2019 at 06:09 | Last modified: January 15, 2019 09:57I e-mailed our author giving some general feedback about the report.
The first paragraph was the focus of my discussion from last time:
> I’ve gone over it extensively and there’s a lot I have to
> say. I don’t have solutions for some of the concerns and
> it’s possible that these particulars have no correct answers
> at all. It’s a complicated project with many permutations.
>
> I would like to see a consistent set of statistics provided
> after every single backtest. The “hypothetical portfolio
> growth” graph template is consistent. The statistics vary
> widely. I often wanted more than what you provided.
Part of this standard battery should have been PnL per day, which our author did not really discuss.
> I would also like to see complete methodology given for
> every backtest. The methodology should allow me to
> replicate your study and get the same/similar results.
>
> No explanation was given for the disappearance of
> 2007-9 data in Sct 5… It really should be in the report…
> because it could otherwise be construed as curve fitting…
> 2008 provided one of the great market shocks of all
> time and we could really benefit by seeing how the
> final trading system performed during that time.
I have since learned the data was lost because she switched from ETF to index data. The latter was only available from 2010 onward. If it meant losing 2007-9, then I think she should have stuck with the ETF.
> I wondered why some components of Scts 3-4 were not
> in Sct 5 and vice versa. How would time and delta stops
> have fared in Sct 3? How would a VIX filter and rolling
> up the put performed in Sct 5? It’s hard to compare
> Sct 5 with Scts 3-4 because of these key differences
> (along with the missing 2007-9 data).
She does not include transaction fees in the backtesting. This is a fault. I mentioned this in the second-to-last paragraph of Part 36 and the fourth paragraph of Part 38.
On several occasions (e.g. paragraph after sixth excerpt here and paragraph after first table here), I wrote “when something changes without explanation, the critical analyst should ask why.” She should be ahead of this and check herself for such inconsistencies throughout. A proofreader could help.
I have mentioned proofreading a couple times (e.g. Parts 36 and 38) and sloppiness many times in this review. Absence of that “hypothetical computer simulated performance” disclaimer was sloppy and plagued me throughout much of the report. A proofreader should have caught this.
A proofreader educated about trading system development could have flagged sloppiness suggestive of curve fitting (e.g. second paragraph below table here) and future leaks (e.g. this footnote and third paragraph below last excerpt here).
Sample sizes should always be given and the report (e.g. third paragraph below third excerpt here and first bullet point below table here) would be better with inferential statistics [testing] to identify the real differences (e.g. third paragraph below first table here and second paragraph below final excerpt here). Criteria for adopting trade guidelines should be detailed at the top. Control group performance would also be useful (e.g. paragraph below graph here and third paragraph following table here).
In conclusion, I think the report would be better described as a trading strategy than a fully developed system. With regard to the latter, though, the report is a great educational piece and a valuable springboard for further discussion.
Categories: System Development | Comments (0) | PermalinkShort Premium Research Dissection (Part 40)
Posted by Mark on July 8, 2019 at 07:14 | Last modified: January 11, 2019 09:18By way of recap, let’s begin by doing an updated parameter check (see second paragraph here). Get your reading glasses:
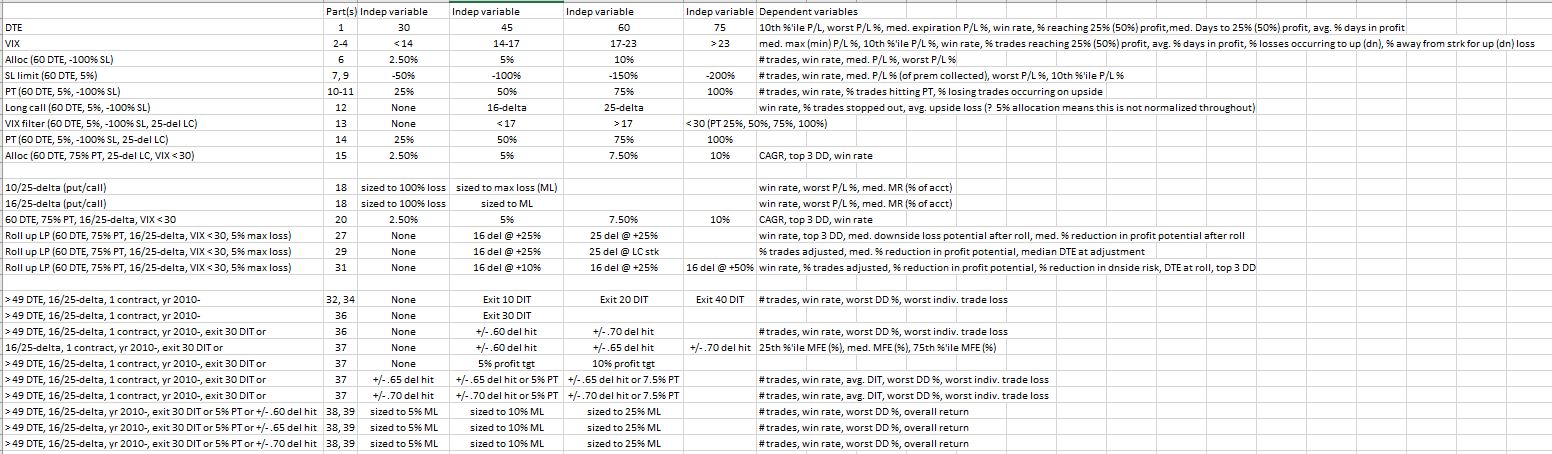
The second column shows in what part of this blog mini-series each study is discussed.
This is too complex to be a definitive exercise in trading system development. Numerous independent variables, dependent variables, and criteria of all sorts have been covered. With all the degrees of freedom represented, only a fraction of the total number of permutations are actually explored.
I discussed my concept of trading system development in the paragraphs #2 and #3 below the excerpt here. As mentioned in the second and third paragraphs of Part 11, thousands of different permutations is too complex. The scary thing is that in some instances (e.g. paragraph after graph here and paragraph #2 here where I discussed failure to explore range extremes), I have actually been clamoring for more parameter values to be studied.
I believe each independent variable should be studied separately to understand its impact on performance.* “Independent variable” is easily confused with words like entry/exit criteria, profit target, filters, stops—when in fact they all probably represent degrees of freedom. The total number of permutations is multiplicative across the number of potential values for each independent variable. I tracked this earlier (final sentence of Part 11) before the research went in too many directions with too many inconsistencies and too much sloppiness.
Some of the tested variables are more about position sizing than trade setup. I’m talking about delta selection for long options. Narrower spreads carry lower margin requirements and allow for greater leverage (see discussion beginning here). This makes delta a factor in position sizing, which goes hand-in-hand with allocation: something she does study.
An entire knowledge domain exists to solve the problem of optimization. I have yet to write about this subject.
For now, it will suffice to say that although I think our author has failed to undertake a valid system development process, I do not have the solution to right her ship. The approach seems too multi-dimensional. In my gut, I sometimes feel that not everything needs to be thoroughly explored. For example, why not just stick with 60 DTE rather than having to look at 30, 45, and 75 DTE? This is precisely the rationale for studying daily trades (second-to-last paragraph here), though, as a check to ensure results aren’t fluke. It’s really all about cutting through the laziness.
I will conclude next time.
* This is easier said than done as interaction effects (see this footnote) should also be identified.
Categories: System Development | Comments (0) | PermalinkShort Premium Research Dissection (Part 39)
Posted by Mark on July 5, 2019 at 07:03 | Last modified: January 11, 2019 08:33Continuing on with our author’s final analysis, she presents two “hypothetical portfolio growth” graphs for each of three delta stops: one with curves for 5% and 10% allocation and one with a curve for 25% allocation. Y-axis values and derived percentages are therefore relevant (see second-to-last paragraph here). None of these final graphs has a referent for the asterisk,* which we now know corresponds to the “hypothetical computer simulated performance” disclaimer shown here.
For each delta stop, she provides the usual table that falls short of the standard battery (second paragraph):
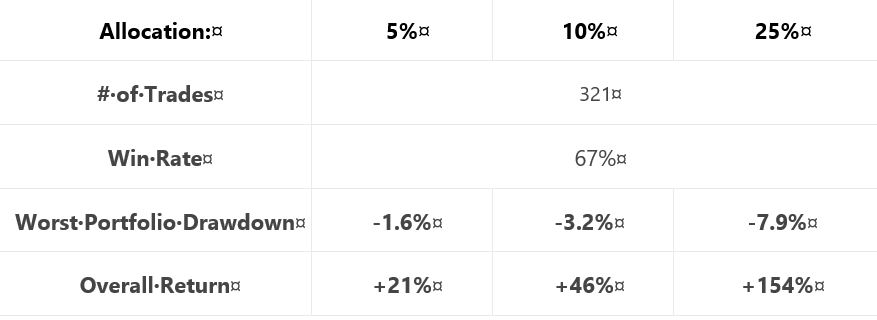
Similar to tables included previously (e.g. Part 15 and Part 20), a couple differences are noteworthy. First, she includes only the biggest rather than top 3 drawdowns (discussed in paragraph #2 below excerpt #1 here). This is characteristic of all tables in this final section (along with the lost 2007-2009 data, which was discussed in these final three paragraphs).
The other difference is inclusion of overall return rather than CAGR. As described in the paragraph below the first table here, things are sloppy when inconsistent from one sub-section to the next. This is the first time we are seeing “overall return.” Also as discussed in that same paragraph, the critical analyst should ask “why” when something changes without explanation. It’s no big deal here either, though. While overall return impresses more (larger in magnitude), CAGR works fine.
I have been calculating CAGR/MDD throughout this mini-series (e.g. Parts 33, 25, 22, 21, 20, 15). To convert from overall return, I’d have to approximate the backtesting interval (she never gives us the exact dates). I could then calculate CAGR/MDD, although it would not be comparable to previous sections due to the unexplained lost data.
Another source of significant sloppiness is passive disappearance of the VIX filter. The VIX filter was used in generating the final graph of the previous section (shown here). Like the lost data, the VIX filter has been absent in these “most up-to-date trading rules.” If the filter only comes into play for the 2008 crash, then it may represent curve fitting. Some explanation should be given for its sudden omission to preserve our author’s credibility.
With regard to sizing this strategy per individual risk tolerance, she unfortunately does not backtest an expanded parameter range (Part 38, paragraph #2) to help us truly understand allocation limits.
In the final sub-section, she presents a recent trade that probably serves a marketing purpose more than anything else. It’s always nice to hit the profit target after only five days. Beginning November 2, 2018, it probably was not included in the historical backtesting, which is fine (less fine is the omission of backtesting dates). I think something current stokes confidence more than something stale. I often wonder how many people click to order reports, trading systems, trader education products, etc., from websites with content a few years old at best. The graphs always look good. Only when you look close and dig deeper are you well-poised to identify errors and expose the fiction.
I will begin to wrap things up next time.
* The rare +1 she scored in Part 38 paragraph #4 is effectively offset.
Short Premium Research Dissection (Part 38)
Posted by Mark on July 2, 2019 at 07:22 | Last modified: January 8, 2019 06:42In paragraph #2 below the first table, I said I liked our author’s exploratory backtest to assess the [MFE] distribution.
What I don’t like about this approach is a failure to explore the extremes. I mentioned this in the paragraph after the graph here. Backtesting over a range where results are directly proportional is of limited utility. Backtesting over an expanded range can illustrate floor and ceiling effects, which defines the profitable range. With regard to delta stops (profit target), I would have liked to see 0.60 (2.5%) along with 0.75 – 0.80 (10% – 15%) rather than just 0.65 and 0.70 (5% and 7.5%).
Not only is study of the extremes* useful, I can argue for it to be essential. Exploring the tails can help us understand whether we have a normal, thin-, or fat-tailed distribution. I could imagine our author giving the excuse she wanted to avoid “overwhelming” us with lots of excess data (second paragraph below table here). It’s not excessive, though, and without it we have no reason to think she actually checked it herself. Not checking would be sloppy, superficial research indeed.
In the next sub-section, our author discusses trade sizing and the commission benefits of index vs. ETF trading. Once again (as discussed near the end of Part 36), she promotes a brokerage, which signifies a clear conflict of interest. Discussing commissions but not slippage is, if you think about it, very sloppy. These are the two biggest components of transaction fees, but slippage likely dwarfs commissions. The only place slippage is even mentioned is the “hypothetical computer simulated performance” disclaimer shown here and included in all such graphs this section (+1 on consistency, for once).
The next sub-section is titled “final strategy backtests… with various allocations.” Are we now going to see what trade guidelines have made the final cut?!
No.
She proceeds by showing us “hypothetical performance growth” graphs and cursory trade statistics for a 5% profit target managed at 30 DIT or delta stops of 0.60, 0.65, or 0.70 with allocations of 5%, 10%, or 25%. She then tells us to decide based on our own individual risk (drawdown) tolerance.
For each of the three delta stops, she gives the following [incomplete] methodology:
> Expiration: standard monthly cycle closest to 60 (no less than 50) DTE
> Entry: day after previous trade closed
> Sizing: 5%, 10%, 20% Allocations [emphasis mine]
This is a typographical error: 20% should be 25%. As with the first paragraph below the first excerpt of Part 36, maybe the proofreader fell asleep? Sloppiness has been a recurrent theme throughout.
> Management: exit after 30 days, 5% profit, or at ±0.60 short delta
I will continue next time.
* Incidentally, backtesting over an expanded range would preclude the need for an exploratory
test to determine MFE distribution.
Short Premium Research Dissection (Part 37)
Posted by Mark on June 27, 2019 at 07:02 | Last modified: January 8, 2019 05:53In this “most up-to-date” section (see end Part 31), our author has explored time stops, delta stops, and now profit targets.
As a prelude to determine what profit targets are suitable for backtesting, she gives us this table:
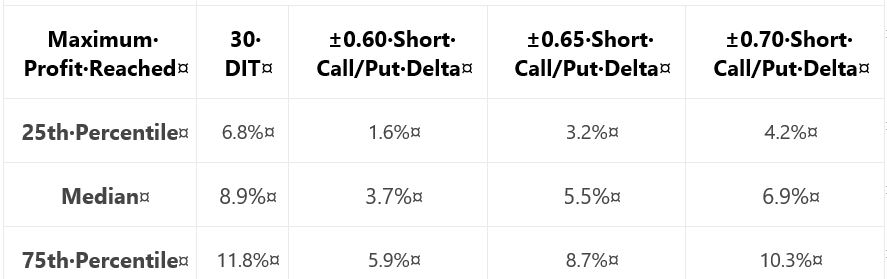
Recall from the end of Part 35 that when something changes without explanation, the critical analyst should ask why. She did not include the 0.65-delta stop last time: why? In this case, it’s no big deal. I like backtesting over a parameter range and having three values across the range is better than two. If only for the sake of consistency, I would have liked to see 0.65 data both times because it feels sloppy when things change from one sub-section to the next.
Adding to the sloppiness, she is once again lacking in methodology detail. I like the idea of probing the distribution to better understand where profit might land. If we can’t replicate, though, then it didn’t happen. Did she backtest:
- Daily trades?
- Non-overlapping trades?
- Winners?
- Winners and losers?
- Any [combinations] of the above?
These factors can all shape our expectations for sample size (which determines how robust the findings may be) and magnitude of averages (e.g. winners will have a higher average max profit than winners and losers. See Part 24 calculations).
She writes:
> Based on the above table, it appears profit targets
> between 5-10% seem reasonable to test for all of the
> approaches except the ±0.60 delta-based trade exits.
She then proceeds to give us “hypothetical portfolio growth” graph #17 with [hypothetical computer simulated performance disclaimer and] 30 DIT, 5% profit target or 30 DIT, and 10% profit target or 30 DIT.
Next, she gives us a “hypothetical portfolio growth” graph and table each for 0.65- and 0.70-delta stops. The graphs are all similar with no allocation, no inferential statistics, and nebulous profitability differences. The tables take the following format:
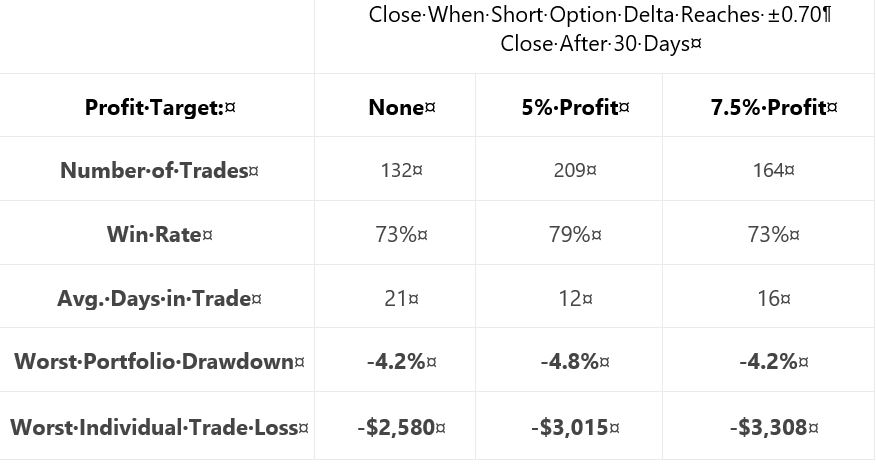
This falls far short of the standard battery and also lacks a complement of daily trade backtesting (see fourth-to-last paragraph here). We still don’t know her criteria for adopting trade guidelines, either. I therefore like her [non-]conclusion:
> After analyzing the various approaches and management
> levels, it seems you could pick any one of the variations
> and run with it. Consistency seems to be more important
> than the specific numbers used to trigger your exits.
She also writes:
> Interestingly, not using a profit target with the ±0.70
> delta-based exit was the ‘optimal’ approach historically.
For this reason and because she did not test [all permutations of] each condition[s], I remain uncertain whether a delta stop is better than any or no time stop. I would say the same about profit target: too much sloppiness and too few methodological details [and transaction fees as discussed at the end of Part 36] to know whether it should make the final cut.
I will continue next time.
Categories: System Development | Comments (0) | PermalinkShort Premium Research Dissection (Part 36)
Posted by Mark on June 24, 2019 at 07:10 | Last modified: January 2, 2019 11:17Picking up right where we left off, our author gives the following [partial] methodology for her next study:
> Expiration: standard monthly cycle closest to 60 (no less than 50) DTE
> Entry: day after previous trade closed
> Sizing: one contract
> Management 1: Hold to expiration
> Management 2: Exit after 30 days in trade (10 DIT)
I think this should be “30 DIT.” The proofreader fell asleep (like third-to-last paragraph here).
Here is “hypothetical portfolio growth graph” #15:
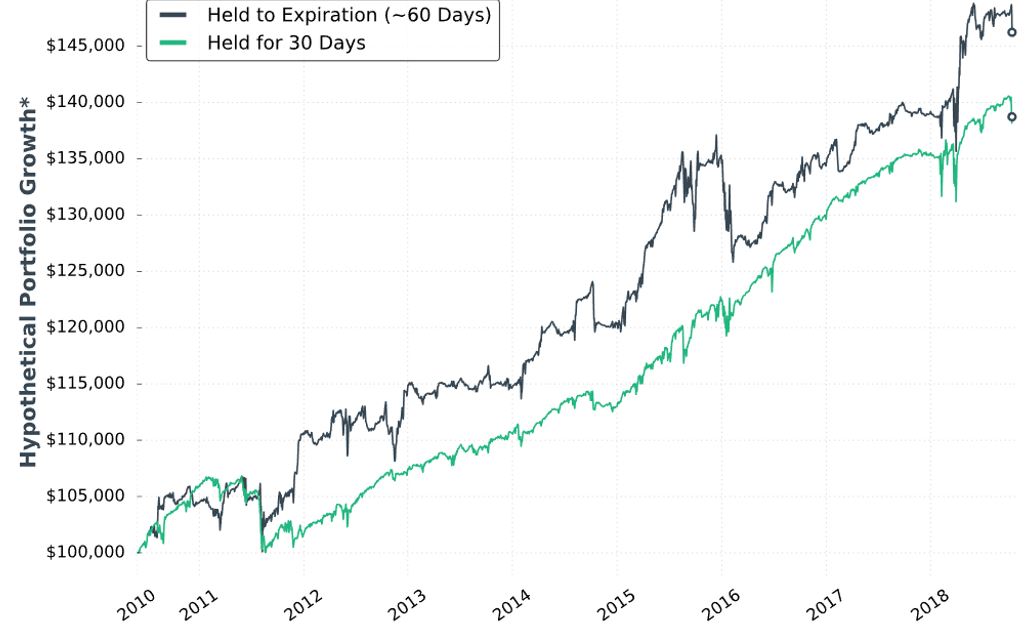
The two curves look different; a [inferential] statistical test would be necessary to quantify this.
She concludes the time stop results in smoother performance and smaller drawdowns. Once again, I’d like this quantified (e.g. the standard battery). I’d also like a backtest of daily trades (rather than non-overlapping) for more robust statistics.
Next, she adds delta stops:
> Management 1: Hold for 30 days (30 DIT)
> Management 2: Exit when short call delta hits +0.60 OR the short put delta hits -0.60
> Management 3: Exit when short call delta hits +0.70 OR the short put delta hits -0.70
I like the idea of a downside stop, but I question the upside stop. With an embedded PCS, we are already protected from heavy upside losses. She does not test downside stop only.
Here is “hypothetical portfolio growth” graph #16:
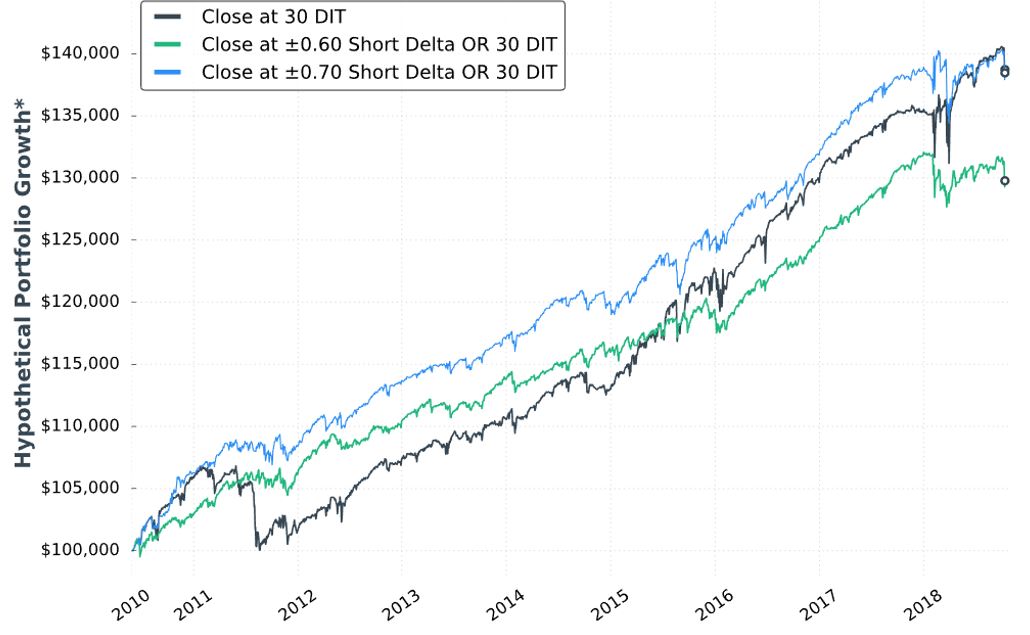
The blue curve finishes at the top and is ahead throughout. The black curve finishes on top of the green, but only leads the green for roughly half the time. Inferential statistics would help to identify real differences.
Thankfully, each of the last two graphs are presented with that “hypothetical computer simulated performance” disclaimer (see second paragraph below graph in Part 34).
Here are selected statistics for graph #16:
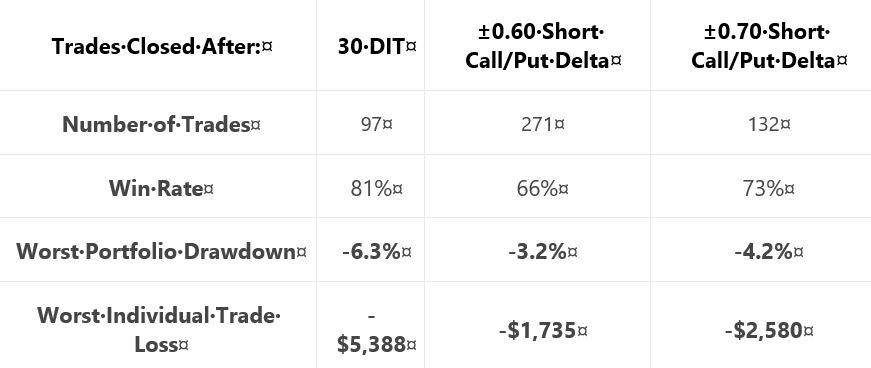
As discussed in the second-to-last paragraph here, percentages are not useful on a graph without allocation. I think relative percentages can be compared, however, when derived on the same allocation-less backdrop.
Unfortunately, we have no context with which to compare total return. As mentioned above, we’re lacking the standard battery (second paragraph) and complement of statistics for daily trades.
As with Part 34, other glaring table omissions include average DIT (to understand impact of delta stops), and PnL per day.
Transaction fees (TF) could adversely affect the delta-stop groups because they include more trades. Our author now mentions fees for the first time:
> …many more trades are made… [with] delta-based exit… we need to
> be considerate of commissions… [At] $1/contract, the ±0.60 delta exit
> would… [generate] $2,168 commissions… if you trade with tastyworks,
> the commission-impact of the strategy could be substantially less…
Unfortunately, she mentions fees only to give a brokerage commercial. Her affiliation with the brokerage is clear because she offers the research report free if you open an account with them. In and of itself, this conflict of interest would constitute a fatal flaw for some.
Discussing commissions but not slippage is sloppy and suspect. It is sloppy because as a percentage of total TF, slippage is much larger than commissions. It is suspect because neither is factored into the backtesting, which makes results look deceptively good.
Thus ends another sub-section with nothing definitive accomplished. She may or may not include time- or delta-based stops in the final system and if she does, then she has once again failed to provide any conclusive backing for either (also see third paragraph below first excerpt here).
Categories: System Development | Comments (0) | Permalink