Short Premium Research Dissection (Part 5)
Posted by Mark on March 7, 2019 at 06:12 | Last modified: November 29, 2018 08:40Section 2 ends with:
> We’ve already covered a great deal of analysis, and we could surely
> continue to analyze market movements/general options strategy
> performance forever.
>
> However, I don’t want to bore you with the details you’re less
> interested in, and I feel we have enough data here to start
> developing systematic options strategies.
I’m not bored because I think raw data like this can be the beginning to meaningful strategy elements (e.g. starting the structure above the money as mentioned in the second paragraph here). Also as discussed in that final paragraph, getting an “accurate documentation of research flow along with everything that was [not] considered, included, or left out” is very important to boost credibility and to make sure real work was done no matter how confusing or boring it may seem. In college, I worked with a lab partner to know the actual work was done. Here, I’m not looking over the author’s shoulder to see her spreadsheets and backtesting engine. How else am I to know the data being presented is real?
I paid good money for this research, which precludes any “less is more” excuse. I am reminded of the third paragraph here. Don’t complain about being overwhelmed by data unless you give me a logical reason why that’s a problem. I want to see as much research as possible to feel confident it’s robust rather than fluke. I want to know the surrounding parameter space was explored as discussed here and here.
A full description of research methodology is very important. I wrote that at the very least, it should be included once per section. The sections in this report are comprised of many sub-sections—sometimes with multiple tables in each. To clarify, then, I would like to see the research methodology in every sub-section if not alongside every single table or graph. Like speed limit signs posted after every major intersection to inform cars regardless of where they turn in, research methodology should be redundant enough to see no matter where I pick up with the reading. The methodology can easily be a footnote(s) to a table or even a reference to an earlier portion of text.
Part 3 of her report continues the discussion of short straddles with the importance of a consistent trade size. She writes:
> If a trader uses a fixed number of contracts per trade, their actual
> trade size would decrease as their account grows, and increase as
> their account falls (generally speaking).
This makes sense for trade size as a % of account value, or relative trade size. Trade size itself, which I think has more to do with notional risk or buying power reduction (BPR), is proportional to underlying price and unrelated to account value.
I would like to see an explanation of BPR for short straddles. We will continue next time to see if this is relevant.
Categories: System Development | Comments (0) | PermalinkShort Premium Research Dissection (Part 4)
Posted by Mark on March 4, 2019 at 06:59 | Last modified: November 27, 2018 10:13She continues with the following table:
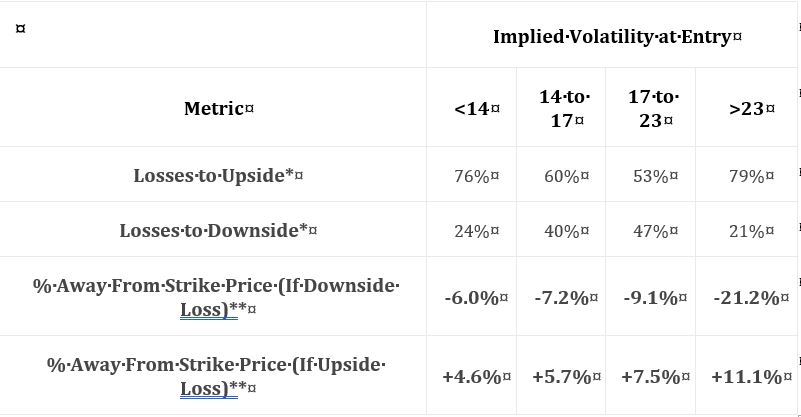
I find this table interesting because it gives clues about how the naked straddle might be biased in order to be more profitable. Once again, the middle two volatility groups show a greater failure rate to the downside. I don’t know why this is and I wouldn’t want to make too much of it especially without knowing whether the differences are statistically significant (see critical commentary in the third-to-last paragraph here). I do see that overall, failure rate is unanimously higher to the upside, which makes me wonder about centering the straddles above the money.
I would like to see the distribution of losing trades over time in order to evaluate stability. Are many losing trades clumped together in close proximity—perhaps in bearish environments? “Since 2007,”* we have been mostly in a bull market. We won’t always been in a bull market. Do the statistics look different for bull and bear? If so, then is there something robust we can use as a regime filter to identify type of market environment? Consider a simple moving average. We could test over a range of periods (e.g. 50 to 250 days by increments of 25) to get sample sizes above and below. We could then look at loss percentages. An effective regime filter would have statistically significantly different loss percentages above vs. below at a period(s) surrounded by other values that also show significant loss percentage differences above vs. below.
The last two rows are not crystal clear. The first row of the previous table (in Part 2) mentioned expiration. I’m guessing these are similarly average percentage price changes between trade entry and expiration. I shouldn’t have to guess. Methodology should be thoroughly explained for every section of text, at least, if not for every table (when needed).
Assuming these do refer to expiration, I would be interested to see corresponding values for winning trades and a statistical analysis with p-value along with sample sizes (as always!). I would expect to see significant differences. Non-significant differences would be an important check on research validity.
I have rarely found things to go perfectly the first time through in backtesting. While it might look bad to see confirming metrics fail to confirm, a corrective tweak would go a long way toward establishing report credibility. As a critical audience, which we should always be if prepared to risk our hard-earned money in live-trading, it is very important to see an accurate documentation of research flow along with everything that was [not] considered, included, or left out. Remember high school or college lab where you had to turn in scribbly/illegible lab notebooks at the end to make sure you did real work?
* Assuming this descriptor, given several sections earlier, still applies. Even if it does, the
descriptor itself does a poor job as discussed in the second full paragraph here.
Short Premium Research Dissection (Part 3)
Posted by Mark on March 1, 2019 at 07:38 | Last modified: November 17, 2018 12:33Conclusions drawn from the table shown here are debatable.
She writes:
> While it may be counterintuitive, selling straddles in the lowest IV range
> was typically more successful than selling straddles in the middle-two IV
> ranges, despite collecting less overall premium. The reason for this is
> that when the VIX Index is extremely low, the S&P 500 is typically not
> fluctuating very much, which leads to steady option decay that leads to
She provides no data on this, and as an EOD study, large intraday ranges may have been masked altogether. HV or ATR are better indicators for how much the market moved. IV reflects how much the market is expected to move.
> profits for options sellers. The biggest problem with selling options in
> low IV environments is that you collect little premium, which means your
> breakeven points are close to the stock price.
All of this makes obvious sense. I would caution against trying to explain “the reason.” It is a reason but who knows why it is. The only thing that matters is that it was an edge in the past. Part of our job as system developers is to look deeper and see if it was a consistent and stable edge. I think it is also our job when developing systems to determine how likely the edge was to be fluke (see third paragraphs here and here), and what we should monitor going forward to know the edge persists.
Said differently, as system developers we must know what we should be monitoring in real-time to know when the system is broken. Only retrospect can ultimately determine whether a system is broken, but we must have criteria in place such that when we see something reasonably suspicious we can take action (and exit).
She continues:
> Conversely, selling options in the highest IV range has historically
> been successful because you collect such a significant premium, allowing
> the market tons of room to move in either direction while remaining in
> the range of profitability.
As before, this makes obvious sense since the data are consistent with the interpretation (reminds me of the financial media as described in the fourth-to-last paragraph here). Is this truly the reason? Not if we look back 10 years from now and see the data trends reversed.
If I were to include this content at all, I might have phrased it by saying “one way to make sense of these data is to think of low IV as… and to think of high IV as…”
Taking a step back, we do not even know if the groups are actually different without a statistical analysis (see links in the third-to-last paragraph here). And again, we do not know how many trades are in each group.
Moving onto the next table:
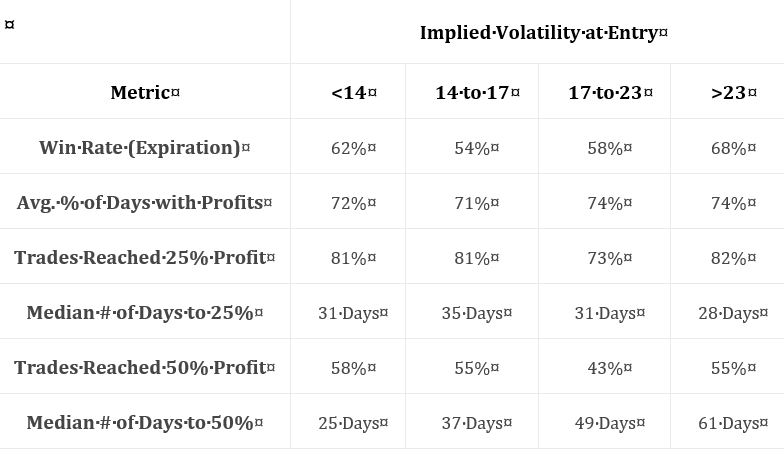
Again, no statistical analysis is performed.
However, I do think it meaningful that all groups showed 73% or more trades hitting 25% profit.
By the way, does this include winners and losers? I think it should include just winners. Do rows 4 and 6 include winners and losers? I think those should include just winners. See my last two paragraphs in Part 2 about lack of transparent methodology.
For kicks and giggles, she then writes:
> But why do the middle-two VIX entry ranges show slightly worse trade
> metrics compared to the lowest and highest VIX entry ranges?
At least she doesn’t try to apply the above explanations for low and high IV to these two groups!
Categories: System Development | Comments (0) | PermalinkShort Premium Research Dissection (Part 2)
Posted by Mark on February 26, 2019 at 07:03 | Last modified: November 16, 2018 15:18I continue today with my critique of some recently-purchased research. This tells a story that should be interesting and compelling to option traders. For this reason, I don’t mind if this mini-series is lengthy.
Skipping ahead a couple sections, this table breaks down straddle data into four categories of VIX level with an equal number of occurrences in each:

Inclusive dates and number of occurrences need to be given every time. The section mentioned in Part 1 said “since 2005” whereas text in this section says “since 2007.” Which is it?
Text in this section says “analyzing these four ranges across four different entry time frames would leave us with an overwhelming amount of data, so we’ll be using the 60-day straddles for this analysis.” I think we can therefore assume 60 DTE.* As a critique, though, I never want to see weak excuses like this when I’ve paid good money to get something. If you told me “data are condensed for simplicity” ahead of time, then I would never have trusted enough to purchase it. This screams “I’m too lazy.” The only reason to condense is for having valid reason to do so.
Row 4 is confusing because it contradicts the first table presented in Part 1 where the worst loss was stated to be -390%. These numbers aren’t anywhere close to that. Row 5, which gives the 10th %’ile to help define the distribution, is more consistent with -390%.
I miss the standard of practice for reliable methodology reporting seen in peer-reviewed scientific literature. The “methods” section of a peer-reviewed article lays out precisely-defined steps that could be followed to repeat the study. I want to see a recap of the methodology used to generate every table and graph shown in a backtesting report (see fifth paragraph here). If presented in the same section, then restatement may not be warranted. At the very least, the first table or graph in every section should be accompanied by well-defined methodology.
If I don’t even have mention of methodology to suggest the author’s head is in the game, then I have added reason to suspect sloppy and inconsistent work. Especially given the fact that people I meet in the trading community are complete strangers, I do not want to assume a thing. It’s my hard-earned money on the line and with all the stiff disclaimers up front, the author is not accountable. This is another reason why I would prefer to do my own research.
* I still want to see number of occurrences for confirmation. I want to see redundant statistics all over
the place to cross-confirm things, really.
Short Premium Research Dissection (Part 1)
Posted by Mark on February 21, 2019 at 06:04 | Last modified: November 16, 2018 15:25I recently purchased research from someone on short premium strategies. In this mini-series I will go through the research with a fine-tooth comb and critique it.
I am going to conduct this analysis in much the same way I have previously dissected investment presentations. Many of these offer mouthwatering conclusions. I think it’s important to smack ourselves whenever we get whiff of something sounding like the Holy Grail. We’re all looking for the Grail and we hope to find it even though, in a separate breath, experienced traders would admit no such Grail exists. Being overtaken by confirmation bias (mentioned twice in the final four paragraphs here and in the fourth paragraph here) can amount to some expensive trading tuition, indeed.
The first thing she does is present basic data on short straddles:
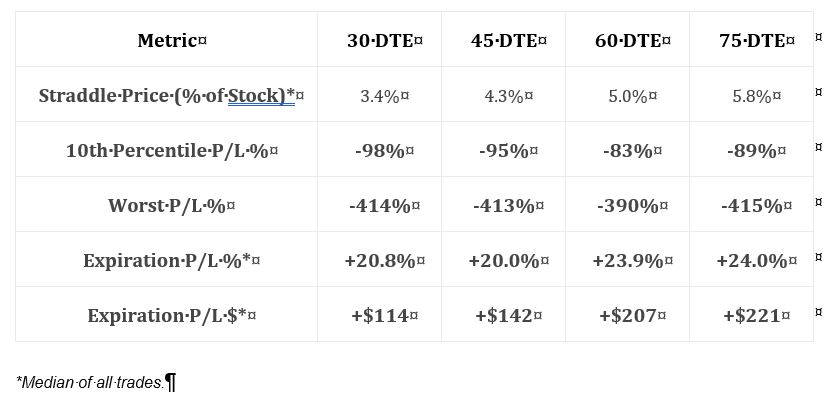
This is an interesting table. I always like to see some reference to “worst trade.” She includes 10th %’ile PnL, which is a great way of giving clues about the PnL distribution. Alone, the average (mean or median) tells very little if the distribution is not Normal. I would have liked to see more percentile data—maybe 5th %’ile (~ 2 SD) and 20-25th %’ile (~ 1st quartile)—to better define the lower tail.
Unfortunately, the methodology used to generate this table is not adequately explained. She writes “2005 to present.” When in 2005? The ending date is also unknown (the document has no publication date, either). The chart implies trades were taken every month at the specified DTE but I need to see total number of trades for verification. Anything more than 30 DTE would result in overlapping trades and much of the document discusses nonoverlapping trades. This could result in a significant sample size difference (larger sample sizes are more meaningful).
Speaking of significant differences, no statistical analysis was applied in this document. This is very unfortunate for reasons discussed here and here. Without number of occurrences and p-values, we cannot put context around whether descriptive statistics are different no matter how they appear.
This table includes more interesting exploratory data:
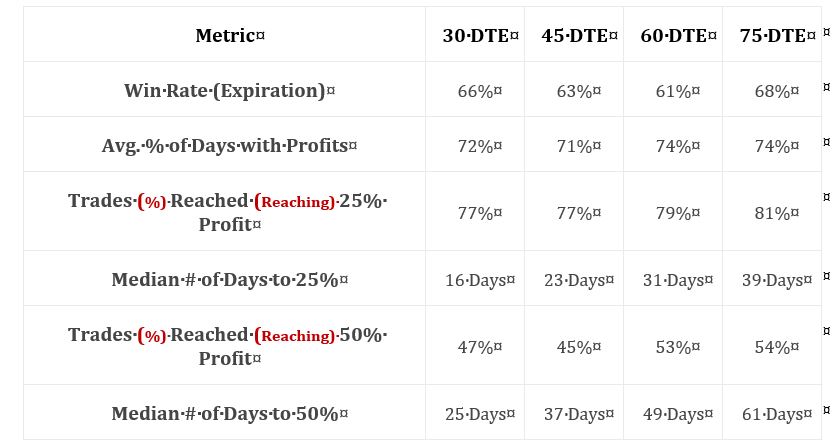
Row 1 indicates suggests a profitable trade, but whether the average trade is profitable depends on the magnitude and distribution (think histogram) of losses. Rows 3 and 5 give insight into the distribution of maximum favorable excursion (see second paragraph here), which can be used to determine profit target. Why set a 50% profit target if only 10% of trades ever reached that level? Rows 4 and 6 give temporal context, which speaks to annualized returns.
I will continue next time.
Categories: System Development | Comments (0) | PermalinkMining for Trading Strategies (Part 3)
Posted by Mark on February 19, 2019 at 05:35 | Last modified: June 18, 2020 11:06I continue today with two more random simulations run on short CL.
Mining 5 is a repeat of Mining 4 (results of which I covered last time) with the same minor change I made to exit criteria. Also as mentioned in Part 2, I am now running the Randomized OOS x3 for confirmation (perhaps two would be sufficient?).
Out of the top 32 (IS) strategies, four demonstrated a lower Monte Carlo (MC) analysis average drawdown (DD) than backtested DD (2007-2015). Three of the four passed Randomized OOS and none passed incubation (2015-2019).
Focusing primarily on Randomized OOS, 14 of the top 33 passed but none passed incubation. Three of the 14 are strategies that passed the MC DD criterion just mentioned.
Because this was not encouraging, I re-randomized the entry criteria, made one change to the exit criteria (see Mining 6), and ran another simulation.
Focusing primarily on the MC DD criterion, 13 out of the top 32 (IS) strategies had a lower average MC DD than backtested DD. Only four of those 13 passed Randomized OOS, and one of those four also passed incubation.
Focusing primarily on Randomized OOS, 12 of the top 32 strategies passed and four of those 12 also passed the MC DD. The only strategy in this simulation to pass incubation was one of those four.
To recap the last few posts, I have run six simulations thus far with my latest methodology. The first simulation was long. This generated six strategies that passed incubation and two that were close (PNLDD 1.70/PF 1.42 and PNLDD 1.98/PF 1.37). The last five simulations were short. Mining 3 produced two strategies that passed incubation. Mining 4 and Mining 6 produced one strategy each that passed incubation.
In other words, Mining 1 was prolific while Mining 2 through Mining 6 were relatively dry. Why might this be?
I am concerned that passing incubation is not so much a matter of whether the strategy is robust as it is a matter of whether the incubation period is favorable for the strategy. If this is true, then should incubation really be the final arbiter? I can imagine a situation where a strategy passes incubation but does not pass either of the other test periods (four years each of IS and OOS); am I to think this strategy is any better than those from my simulations that don’t pass incubation?*
Maybe number of periods passed (e.g. with PNLDD > 2.0 and PF > 1.3) is most important. With each period being slightly different in terms of market environment [whether quantifiable or not], strategies that pass more periods would seem to be most likely to do well in the future when market conditions are likely to repeat (in sufficiently general terms).
This relates back to walk-forward optimization (WFO), but remains slightly different. In WFO, I get multiple test runs by sliding the window forward the length of the OOS period. The big difference there is that the rules can change with each run. What I really want to study are rolling returns (overlapping or not is a consideration) of the same strategy and then select strategies that pass the most rolling periods. Is it possible this could happen by fluke? If so then this approach would be invalidated.
Another possibility is to seek out a fitness function that reflects equity curve consistency. I need to research whether I have this at my disposal and consider what similarities exist compared to a tally of rolling returns.
* — Realize that I don’t incubate unless the strategy does well OOS, passes Randomized
OOS (and/or MC DD), and is reasonably good IS (else it would not have appeared in
the first place and/or would not pass Randomized OOS per third paragraph here).
Mining for Trading Strategies (Part 2)
Posted by Mark on February 15, 2019 at 07:11 | Last modified: June 17, 2020 13:48Today I am going to mine for more trading strategies using the same procedure presented in Part 1.
Today’s strategies will be short CL. See Mining 2 for specific simulation settings.
Seven out of the top 20 (IS) strategies passed the Randomized OOS test (see fourth paragraph here). None of the seven had a PNLDD > 1 in the 4-year incubation period, or a PF > 1.24.
Six of the top 30 had an average Monte Carlo drawdown (DD) less than backtested DD. Only two of the six passed Randomized OOS. I did not run the others through incubation.
Not happy with this, I ran another simulation (see Mining 3) for short CL strategies the very next day.
Nine out of the top 28 (IS) strategies passed Randomized OOS. With PNLDD > 2 and PF > 1.30, two of these nine passed incubation. Five of these nine had an average Monte Carlo DD < backtested DD, but none of those passed incubation. Thirteen of the top 28 strategies had an average Monte Carlo DD < backtested DD, but none of these passed incubation.
Still not impressed, I changed the exit criteria slightly for my next short CL simulation (see Mining 4).
Twenty-two of the top 31 (IS) strategies passed Randomized OOS. One of these 22 passed incubation (PNLDD 2.44, PF 1.57). Five of these 22 had an average Monte Carlo DD < backtested DD, but none of the five passed incubation.
Running this simulation generated 22 strategies that passed Randomized OOS but only one that passed incubation (and none that passed those + Monte Carlo DD). I questioned the utility of looking at so many Randomized OOS graphs since such a small percentage pass but on second thought, viewing more is necessary for exactly that reason.
I have seen strategies pass Randomized OOS once but fail to repeat. With Monte Carlo DD, I run the simulation three times for confirmation. I will do the same for Randomized OOS going forward. I also thought about requiring both OOS and IS equity curves to be all above zero for Randomized OOS. The hurdle is high enough already, though, so I will hold off on the latter and just focus on requiring multiple passing Randomized OOS results to confirm.
Categories: System Development | Comments (0) | PermalinkMining for Trading Strategies (Part 1)
Posted by Mark on February 12, 2019 at 06:10 | Last modified: June 18, 2020 05:33On the heels of my validation work with the Noise Test and Randomized OOS, I am going to proceed with a new methodology to develop trading systems.
I built today’s strategies in the following manner:
- Random 2-rule long CL with basic exit criteria (see Mining 1)
- Test period 2007 – 2015
- Second half of test period designated as OOS
- Strategies sorted by OOS PNLDD
- Searched on first page of simulation results for strategies that passed Randomized OOS
- Retested passing strategies from 2015 – 2019 (“incubation”)
- Looked for strategies with 4-year PNLDD > 2 and PF > 1.30 during incubation
The incubation criteria are nothing magical. I found a couple handfuls of decent-looking strategies and settled upon these numbers after seeing the first few (the numbers were actually lowered somewhat by the end). Also, more than anything else at this point I am trying to gauge whether Randomized OOS is at all helpful to screen for new strategies; a specific critical value will hopefully be determined in the future.
Of the top 28 strategies (all had PNLDD > 3.3 OOS and PF > 1.48 OOS), 21 passed Randomized OOS. Many of these satisfied DV #2 for the IS portion as well, but I did not require that in order to pass.
Nine of 21 strategies met the lowered incubation criteria with PNLDD > 1.68 and PF > 1.28.
On the Monte Carlo Analysis, I look for average drawdown (DD) to be less than the backtested strategy DD. This is mentioned by the software developers as a metric to provide confidence that performance statistics are not artificially inflated due to luck. I have not yet tested this, but I am monitoring it.
In the current simulation, zero of 10 strategies that met the lowered incubation criteria had Monte Carlo DDs less than backtested. None of the other 11 strategies that passed Randomized OOS did either.
I have no major takeaways right now since I am early in the data collection stage. What percentage of strategies pass Randomized OOS? What percentage of strategies have MC DDs less than backtested? What percentage of strategies go on to pass incubation? What kind of performance deterioration can I expect going from IS to OOS to incubation?? How often will I find a strategy that does not follow this pattern?
The software is advertised to come standard with an arsenal of tools capable of stress testing strategies. If passing those stress tests is not correlated with profitable strategies, then we will have an ugly disconnect.
For now, though, all I need are more simulations, more samples, and more data.
Categories: System Development | Comments (0) | PermalinkTesting the Randomized OOS (Part 4)
Posted by Mark on February 7, 2019 at 07:33 | Last modified: June 15, 2020 10:50I ran into a snafu last time in trying to think through validation of Randomized OOS. Today, let’s try to get back to basics.
The argument for Randomized OOS seems strong as a test of OOS robustness for different market environments. By analyzing where the original backtest fits within the simulated distribution (DV #1), I should be able to get a sense of how fair the OOS period is and whether it contributes positively or negatively to OOS results. Also, if all simulations are above zero (DV #2) then I feel more confident this strategy is likely to be profitable during the time period studied.
In the same breath, Randomized OOS is a reflection of IS results. The better IS performance, the greater the chance for better scores on DV #1 and DV #2. I could look at the total equity curve and separately evaluate IS vs. OOS, but I think the stress test may portray this more clearly.
To make for a viable strategy, I want the actual backtested OOS equity to be in the lower 2/3 of the simulated distribution and a Yes on DV #2. I also want to see decent IS performance, but the latter is probably redundant if I am looking at Randomized OOS. My study, then, is to determine whether strategies that pass Randomized OOS are more likely to go on to produce profitable results in the future (similar to this third paragraph).
Perhaps the highest-level study I can do with the software is to build the best strategies and see what percentage proceed to do well* afterward. Since the software builds strategies based on IS results, I could save time by testing on IS and looking to see what percentage of best strategies do well OOS. This could serve as a benchmark for what percentage of best strategies that also meet stress testing criteria go on to do well. The big challenge is to find strategies that pass the stress tests. This is also the most time-consuming activity.
The latter process, though, is probably already shortened now that I have rejected the Noise Test. Related future studies include exploration of the merits of MC simulation and MC drawdown.
* — Operational definition required. “Do well” could mean positive PNL or
some minimal score on other fitness functions.
Testing the Randomized OOS (Part 3)
Posted by Mark on February 4, 2019 at 07:14 | Last modified: June 15, 2020 07:43Today I continue discussion of my attempt to validate the Randomized OOS stress test.
As I started scoring the OOS graphs, I quickly noticed the best (IS) strategies were associated with all simulated OOS equity curves above zero (DV #2 from Part 1). This seemed much different than my experience validating the Noise Test. I realize comparing the two is not apples-to-apples (i.e. different methodology of stress test, 100 vs. 1,000 simulations, etc.). Nevertheless, this caught my attention since only ~50% (85/167) of the Noise Tests analyzed showed the same thing.
I then realized IS performance directly affects the OOS graph in this test! The simulated OOS equity curves are a random mashup of IS equity and OOS equity. If the IS equity (or any fitness function) is really good then the simulated OOS is going to have a positive bias. If the IS equity is marginal, then it’s going to have a much weaker [but still] positive bias.
I figured my mistake was that I needed to be scoring the IS, not OOS, graphs. I would then be seeing if the best versus not-so-great strategies are associated with any significant difference in DVs #1 and #2. I realized, too, that not all IS strategies had associated OOS data that met my minimum trade number criterion (60). Were this the case, then attempting to run the Randomized OOS test produced an error message forcing me to find another strategy instead. This took more time, but I was able to get through it.
For the same reasoning described two paragraphs above, I now believe this approach to be flawed as well. My best and worst strategies are associated with an unknown variance in OOS performance. This OOS variability prevents me from establishing a direct link between any observed differences and quality of (IS) strategy. All observed differences are due to some unknown combination of IS and OOS variability.
Doing the study this way would require collection of additional data on OOS performance to compare consistency between the groups. A brief review shows 61 out of 167 (36.5%) strategies with profitable OOS periods (and I should probably go through and estimate the exact PnL to get more than nominal data). The higher the OOS PnL, the more upward bias I would expect on the IS distribution. If I have three variables—good/bad IS, not/profitable OOS, and positioning within OOS simulation—then maybe I could run a 3-way ANOVA. Three-way Chi Square? I know correlation cannot be calculated with nominal data.
Honestly, I don’t have the statistical expertise to proceed with an analysis this complex.
At this point, I’m not sure it makes sense to do the study the original way, either. If I scored the OOS graph and tried to look for some relationship with future performance, then I would need to look at IS in order to determine whether something particular about IS leaked into the OOS metrics (DV #1 and DV #2) or whether OOS metrics are the way they are due to actual strategy effectiveness. Some interaction effect seems in need of being identified and/or eliminated.
Well isn’t this just a clusterf—
I will conclude next time.
Categories: System Development | Comments (0) | Permalink