Backtester Variables
Posted by Mark on July 14, 2022 at 06:44 | Last modified: June 22, 2022 08:34Last time I discussed modules including those used by an early version of my backtester. Today I introduce the variables.
For any seasoned Python programmer, this post is probably unnecessary. Not only can you understand the variables just by looking at the program, the names themselves make logical sense. This post is really for me.
Without further ado:
- first_bar is Boolean to direct the outer loop. This could be omitted by manually removing the data file headers.
- spread_count is numeric* to count number of trades.
- profit_tgt and max_loss are numerics. These could be made customizable or set as ranges for optimization.
- missing_s_s_p_dict is a dictionary for cases where long strike is found but short strike is not.
- control_flag is string to direct program flow (‘find_long’, ‘find_short’, ‘update_long’, or ‘update_short’).
- wait_until_next_day is Boolean to direct program flow.
- trade_date and current_date are self-explanatory with format “number of days since Jan 1, 1970.”
- P_price, P_delta, and P_theta are self-explanatory with P meaning “position.”
- H_skew and H_skew_orig are self-explanatory with H meaning “horizontal.”
- L_iv_orig and S_iv_orig are long (L) and short (S) original (at trade inception) option IV.
- ROI_current is current (or trade just closed) trade ROI.
- trade_status is a string: ‘INCEPTION’, ‘IN_TRADE’, ‘WINNER’, or ‘LOSER’.
- L_dte_orig and S_dte_orig are days to expiration for long and short options at trade inception, respectively.
- L_strike and S_strike are strike prices (possibly redundant as these should be equal).
- L_exp and S_exp are expiration dates with format “number of days since Jan 1, 1970.”
- S_exp_mo and L_exp_mo are expiration months in 3-letter format.
- L_price_orig and S_price_orig are option prices at trade inception.
- L_delta_orig and S_delta_orig are delta values at trade inception.
- L_theta and S_theta are current theta values.
- spread_width is number of days between long- and short-option expiration dates.
- P_t_d_orig and P_t_d are original and current TD ratio, respectively.
- PnL is trade pnl.
- test_counter counts number of times program reads current line (debugging).
- trade_list is list of trade entry dates (string format).
- P_price_orig_all is list of trade inception spread prices (for graphing purposes).
- P_theta_orig_price (name needs clarification) is position theta normalized for spread price at trade inception.
- P_theta_orig_price_all is list of position theta values normalized for spread price at trade inception (graphing).
- P_theta_all is list of position theta values at trade inception (graphing).
- feed_dir is path for data files.
- strike_file is the results file.
- column_names is first row of the results file.
- btstats is dataframe containing the results [file data].
- mte is numeric input for minimum number of months until long option expiration.
- width is numeric input for number of expiration months between spread legs.
- file is an iterator for data files.
- barfile is an open data file.
- line is an iterator for barfile.
- add_btstats is a row of results to be added to dataframe.
- realized_pnl is self-explanatory numeric used to calculate cumulative pnl.
- trade_dates_in_datetime is list of string (rather than “days since Jan 1, 1970”) trade entry dates.
- marker_list is list of market symbols ( ‘ ‘ or ‘d’).
- xp, yp, and m are iterators to unpack dataframe elements for plotting.
- ticks_array_raw creates tick array for x-axis.
- ticks_to_use determines tick labels for x-axis.
I will have further variables as I continue with program development and I can always follow-up or update as needed.
*—Exercise: write a code overlay that will print out all variable names and respective data types in a program.
Backtester Modules
Posted by Mark on July 11, 2022 at 07:18 | Last modified: June 22, 2022 08:34In Part 1, I reviewed the history and background of this backtester’s dream. I now continue with exploration of the backtesting program in a didactic fashion because as a Python beginner, I am still trying to learn.
Modular programming involves cobbling together individual modules like building blocks to form a larger application. I can understand a few advantages to modularizing code:
- Simplicity is achieved by allowing each module to focus on a relatively small portion of the problem, which makes development less prone to error. Each module is more manageable than trying to attack the whole beast at once.
- Reusability is achieved by applying the module to various parts of the application without duplicating code.
- Independence reduces probability that change to any one module will affect other parts of the program. This makes modular programming more amenable to a programming team looking to collaborate on a larger application.
The backtester is currently 290 lines long, which is hardly large enough for a programming team. It is large enough to make use of the following modules, though: os, glob, numpy, datetime, pandas, and matplotlib.pyplot.
I learned about numpy, datetime, pandas, and matplotlib in my DataCamp courses. I trust many beginners are also familiar so I won’t spend dedicated time discussing them.
The os and glob modules are involved in file management. The backtester makes use of option .csv files. According to Python documentation, the os module provides “a portable way of using operating system dependent functionality.” This will direct the program to a specific folder where the data files are located.
The glob module “finds all the pathnames matching a specified pattern according to the rules used by the Unix shell, although results are returned in arbitrary order.” I don’t know what the Unix shell rules are. I also don’t want results returned in arbitrary order. Regardless of what the documentation says, the following simple code works:
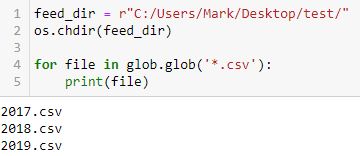
I created a folder “test” on my desktop and placed three Excel .csv files inside: 2017.csv, 2018.csv, and 2019.csv. Note how the filenames print in chronological order. For backtesting purposes, that is exactly what I need to happen.
Functions are a form of modular programming. When defined early in the program, functions may be called by name at multiple points later. I did not create any user-defined functions because I was having trouble conceptualizing how. The backtester does perform repetitive tasks, but loops seems sufficient do the work thus far.
If functions are faster, then it may worth making the change to implement them. As I go through the program more closely and further organize my thoughts,* I will be in a better position to make this assessment.
*—Don’t get me started on variable scope right now.
Resolving Dates on the X-Axis (Part 2)
Posted by Mark on June 17, 2022 at 06:45 | Last modified: April 4, 2022 14:47Today I conclude with my solution for resolving dates as x-axis tick labels.
I think part of the confusion is that to this point, the x-coordinates of the points being plotted are equal to the x-axis tick labels. This need not be the case, though, and is really not even desired. I want to leave the tick labels as datetime so matplotlib can automatically scale it. This should also allow matplotlib to plot the x-values in the proper place.
Documentation on plt.xticks() reads:
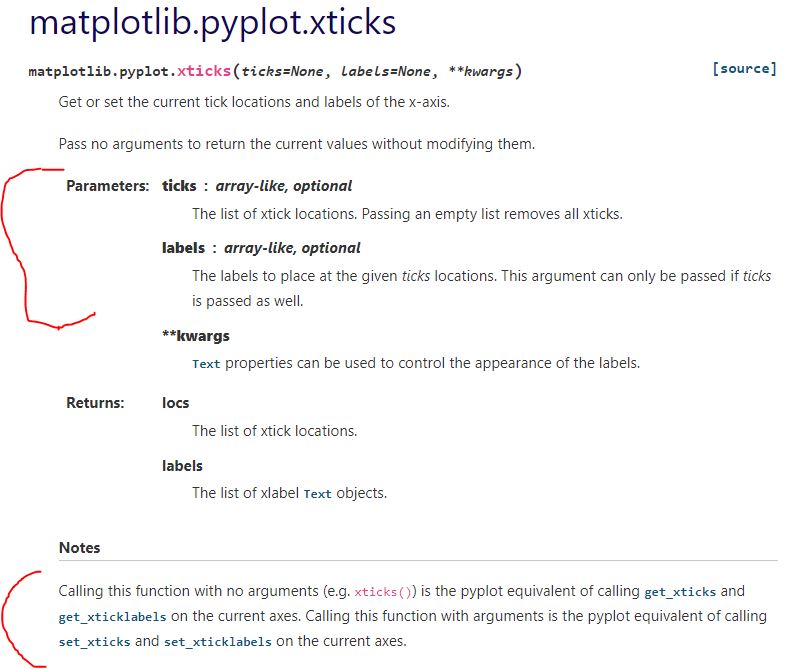
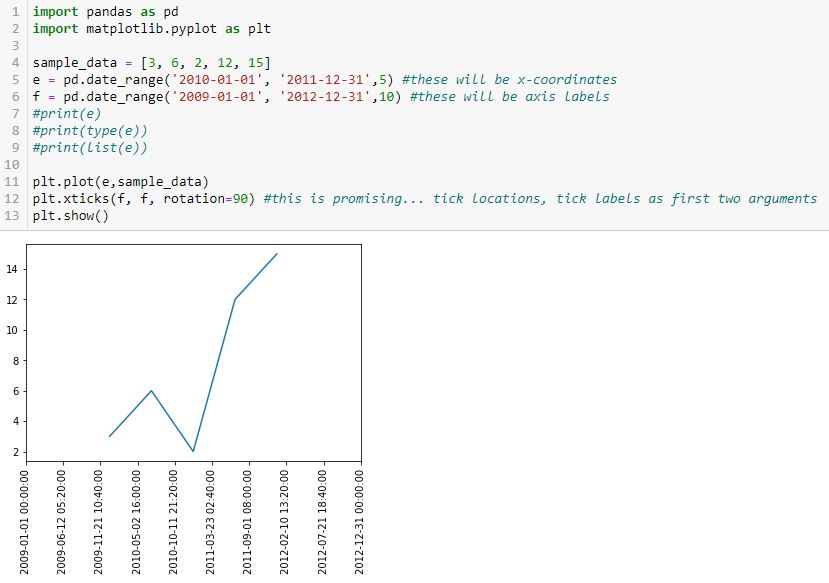
The first segment suggests I can define the tick locations and tick labels with the first two arguments. For now, those are identical. Adding c as the first two arguments in L11 (see Part 1) gives this:
Ah ha! Can I now insert a subset as a different time range for the x-coordinates?
I think we’re onto something! I commented out the print lines in the interest of space.
Finally, let’s reformat the x-axis labels to something more readable and verify datatype:
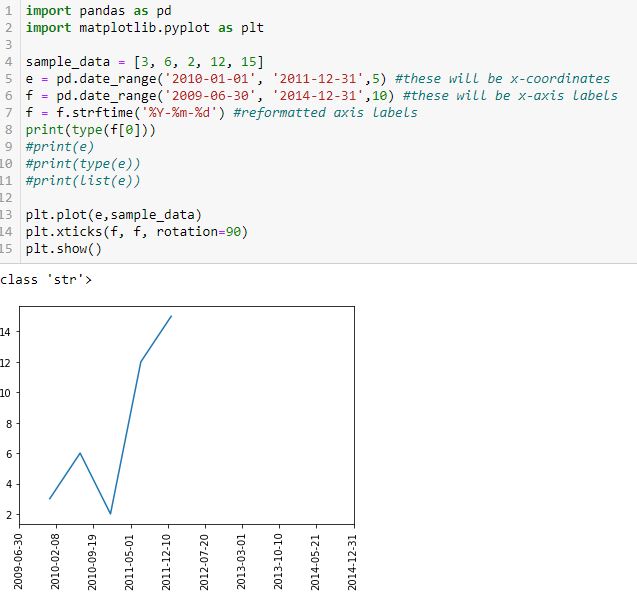
Success! I am able to eliminate hours, minutes, and seconds. Interestingly, the axis labels now show up as string but matplotlib is still able to understand their values and plot the points correctly (I suspect the latter takes place before the former). Changing the date range on the axis helps because this graph should look different from the previous one.
To put in more object-oriented language:
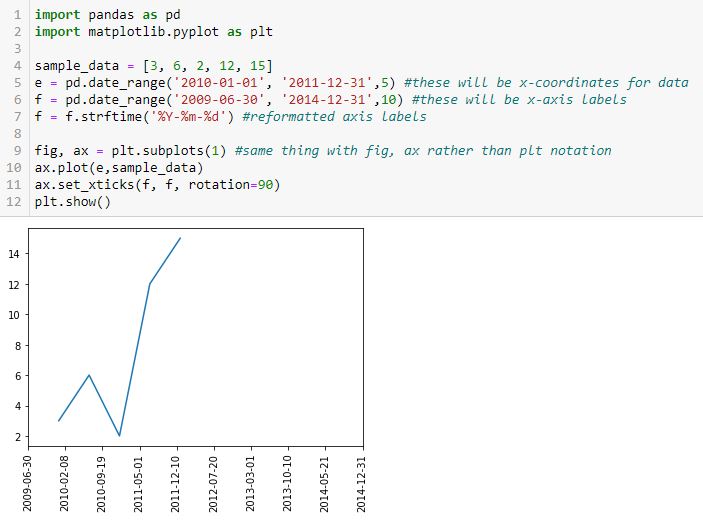
I suspect the confusion between the plt and fig, ax approaches is widespread. For a better explanation, see here or here.
Categories: Python | Comments (0) | PermalinkResolving Dates on the X-Axis (Part 1)
Posted by Mark on June 14, 2022 at 06:32 | Last modified: April 4, 2022 14:04Having previously discussed how to use np.linspace() to get evenly-spaced x-axis labels, my final challenge for this episode of “better understanding matplotlib’s plotting capability” is to do something similar with datetimes.
This will be a generalization of what I discussed in the last post and as mentioned in the fourth paragraph, articulation of exactly what I am trying to achieve is of the utmost importance.
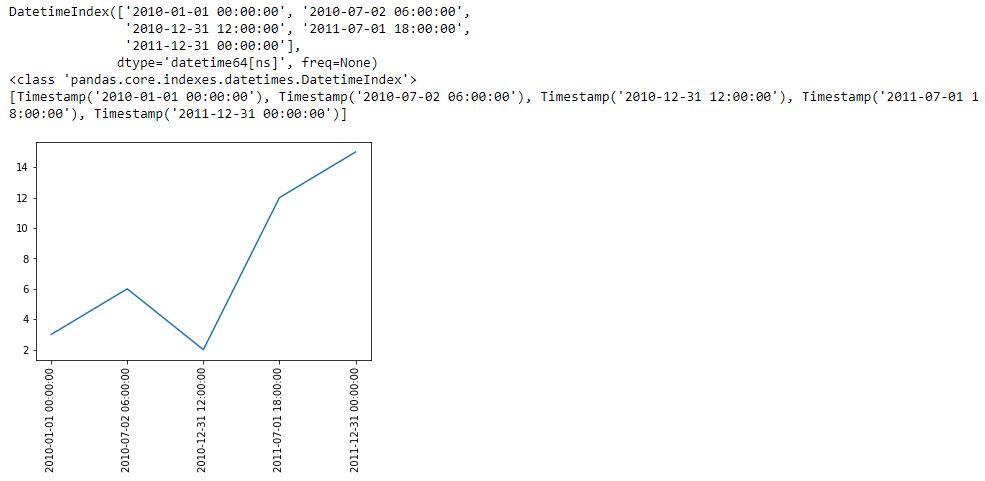
I begin with the following code and a new method pd.date_range():
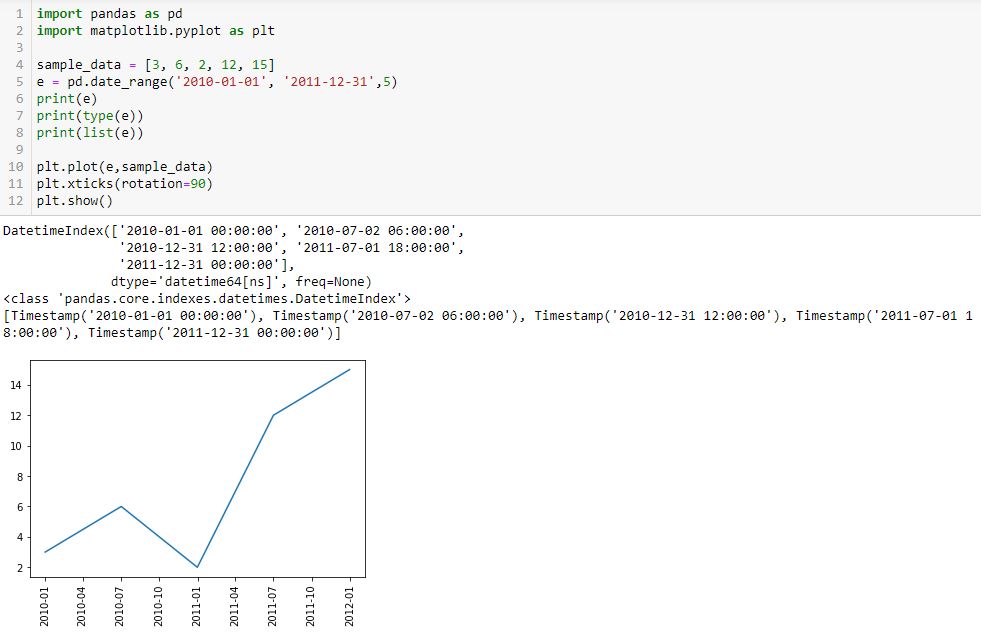
L5 generates a datetime index that I can convert to a list using the list() constructor (see output just above graph). Each element of the subsequent list is datatype pd.Timestamp, which is the pandas replacement for the Python datetime.datetime object. Observe that the first and second arguments are start date and end date, which are included in the Timestamp sequence. Also notice that the list has five elements, which is consistent with the third argument of pd.date_range().
Given a start date, end date, and n labels, this suggests I can generate (n – 1) evenly-spaced time intervals. Great start!
The enthusiasm fades when looking down at the graph, however. First, I get nine instead of five tick labels. Second, my desired format is yyyy-mm-dd as contained in L5. I do not know how/where the program makes either determination.
Another problem is that if I change the third argument (L5) to 15 to get more tick labels, a ValueError results: “x and y must have same first dimension, but have shapes (15,) and (5,).” That makes sense because I now have an unequal number of x- and y-coordinates. This date_range is really intended to be used only for tick labels and not as the source of x-coordinates. I may need to create a separate date_range (or make another list of x-coordinates) for plt.plot() and then create something customizable for evenly-spaced datetime tick labels.
I will continue next time.
Categories: Python | Comments (0) | PermalinkResolving the X-Axis (Part 2)
Posted by Mark on June 9, 2022 at 07:22 | Last modified: March 31, 2022 17:30I left off last time with a promising solution for setting x-axis labels using the Matplotlib.Ticker.FixedLocator Class. Unfortunately, the example at the bottom shows this doesn’t work for all values, which calls the solution into question.
What’s going on? Take a look at the following code snippet:
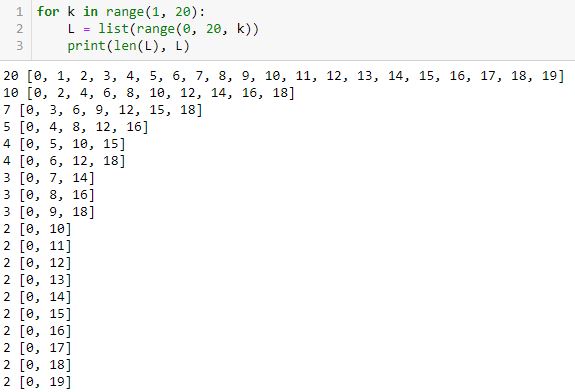
This shows for equally-spaced tick labels having integer coordinates, only certain numbers of labels are possible: 2, 3, 4, 5, 7, 10, and 20. I did not get six because it’s not mathematically possible. The same holds true for 8-9 and 11-19. When multiple equally-spaced lists are possible, I was really aiming for the one with the last element closest to the final date in the list.
In order to code this stuff accurately, I need to articulate exactly what I’m trying to achieve. I failed to do that.
Aside from the FixedLocator Class, another way to approach this is with np.linspace(a, b, c). This automatically creates a linear space of c-point subdivisions between a and b inclusive (i.e. a and b always included as the first and last values):
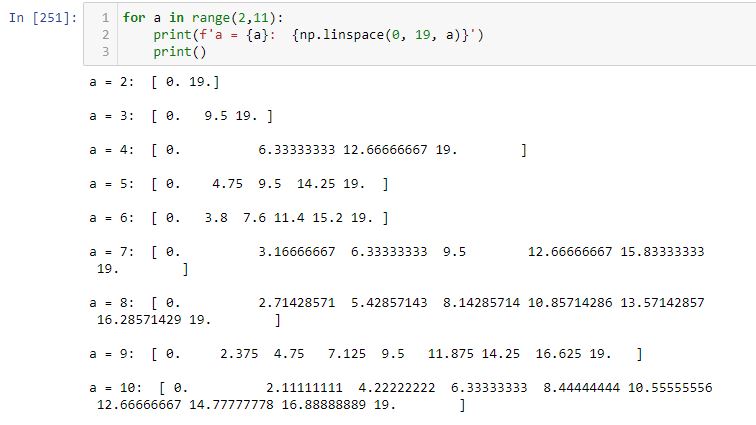
Note how each list begins and ends with 0 (a) and 19 (b), respectively.
How do the plots look with different numbers of x-axis labels?
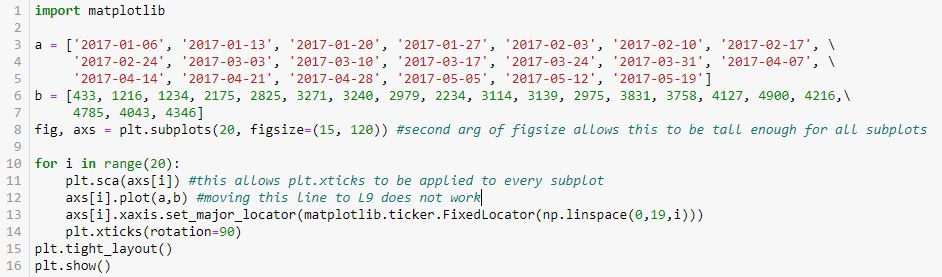
In the interest of space, I will describe rather than show the output. We get 20 subplots where the number of tick labels increases from zero to 19 by an increment of one for each subplot. The graphs are identical—the only thing that changes is the number of equally-spaced tick labels. Outstanding!
Some highlights of this code are as follows:
- The figure and axes are drawn in L8.
- L8 also includes the figsize argument to make the graphs larger (see second paragraph of Part 1).
- plt.sca(), as originally shown in L35 of this second code snippet, rotates x-axis labels for each subplot (a simple thing that took major work to figure out).
- L10 and L13 are basically applying the np.linspace() exercise shown above to the x-axis labels on the subplots.
I’m quite happy with the progress made here!
Categories: Python | Comments (0) | PermalinkResolving the X-Axis (Part 1)
Posted by Mark on June 6, 2022 at 07:30 | Last modified: March 31, 2022 11:52As it turns out (see here and here), some of the matplotlib debugging came down to better understanding the zip() method. I still have some further considerations to resolve.
I would like to enlarge the graph so the axis isn’t so crowded when every label is included.
First though, I want the x-axis tick labels and locations to be handled automatically. I want z labels spaced evenly throughout the time interval from first Friday to last Friday. Alternatively, I may want to try plotting labels only where new trades begin.
When left to plot the x-axis tick labels automatically, others were seeing consistent tick labels on the 1st and 15th of each month as discussed in the third paragraph of Part 7. That would be acceptable, but for some unknown reason, I got asymmetric labels on the 1st and 22nd of each month as shown near the bottom here.
I stumbled upon the Matplotlib.ticker.FixedLocator Class, which is seen in L10 below:
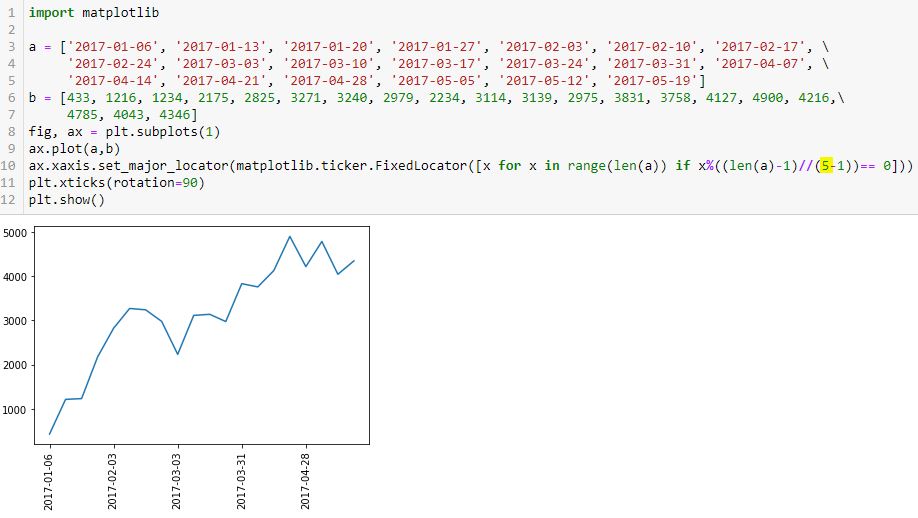
The highlighted number is the number of tick labels that I expect to see. I determined this by trial and error (it requires the minus one). I want constant spacing across these labels and eventually, I’d like the program to calculate the optimal number.
Let’s break this down to see how it works (or not):
> [x for x in range(len(a)) if x%((len(a)-1)//(5-1))== 0]
This is a pretty complicated piece of code for a beginner (me). First, we have to recognize it as a list comprehension: it will generate a list. A list will direct the program to place tick labels at specified locations as shown just above the first graph here.
The list will be generated as follows:
- len(a) is 20 (items in list a).
- range(20) creates a range object starting from 0 and going to 19.
- x for x in range(len(a)) will iterate over the range object and place each entry in the list…
- …if the subsequent condition is met.
- Subsequent condition involves the modulo operator (%), which calls for division remainder.
- Numerator is x.
- Denominator is (len(a)-1) // (5-1)
- // is floor division, which truncates any remainder.
- len(a)-1 // (5 – 1) = (20 – 1) // 4 = 19 / 4 = 4.75, which gets truncated to 4.
- Subsequent condition therefore calls for multiples of 4 (x / 4 will have remainder == 0).
- From 0 to 19, multiples of 4 are: 0, 4, 8, 12, and 16.
- These are exactly the dates shown as x-axis labels (count L3 – L5 dates with first being #0).
If I populate the highlighted number as 1, then I’ll get division by zero (not good). I’d never want just one tick label anyway. Two works along with 3, 4, and 5.
What about 6?
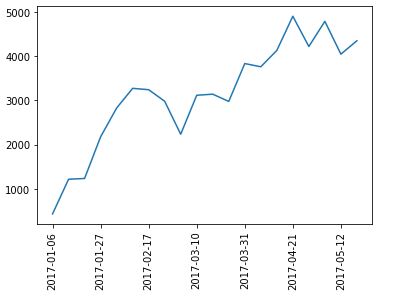
I count seven tick labels.
Houston, we have a problem.
Categories: Python | Comments (0) | PermalinkUnderstanding the Python Zip() Method (Part 2)
Posted by Mark on June 3, 2022 at 07:26 | Last modified: March 29, 2022 11:39Zip() returns an iterator. Last time, I discussed how elements may be unpacked by looping over the iterator. Today I will discuss element unpacking through assignment.
As shown in case [40] below, without the for loop each tuple may be assigned to a variable:
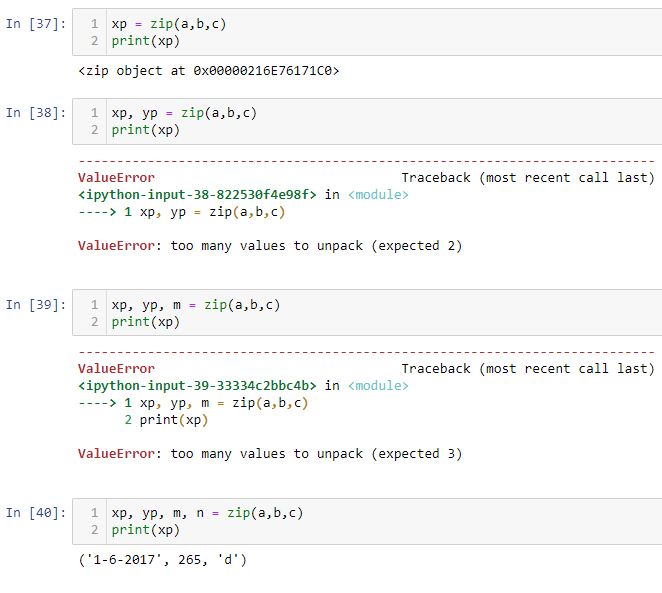
[37] shows that when assigned to one variable, the zip method transfers a zip object. Trying to assign to two or three variables does not work because zip(a, b, c) contains four tuples. As just mentioned, [40] works and if I print yp, m, and n, the other three tuples can be seen:
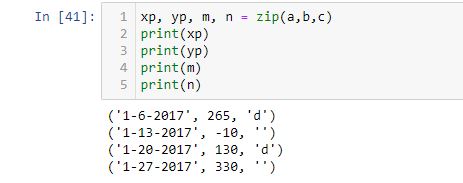
I got one response that reads:
> But since you hand your zip iterables that all have 4 elements, your
> zip iterator will also have 4 elements.
Regardless of the number of variables on the left, on the right I am handing zip three iterables with four elements each.
> This means if you try to assign it to (xp, yp, m), it will complain
> that 4 elements can’t fit into 3 variables.
This holds true for three and two variables as shown in [39] and [38], respectively, but not for one variable ([37]). Why?
Maybe it would help to press forward with [37]:
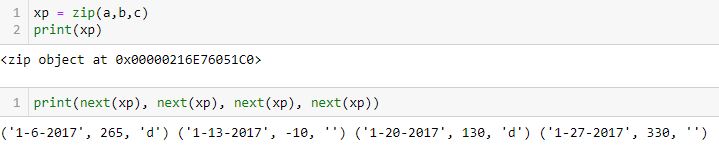
If assigned to one variable, the zip() object still needs to be unpacked (which may also be accomplished with a for loop). If assigned to four variables, each variable receives one 3-element tuple at once.
In figuring this out, I was missing the intermediate step in the [un]packing. zip(a, b, c) produces this series:
(‘1-6-2017’, 265, ‘d’), (‘1-13-2017’, -10, ”), (‘1-20-2017’, 130, ‘d’), (‘1-27-2017’, 330, ”)
or
(a0, b0, c0), (a1, b1, c1), (a2, b2, c2), (a3, b3, c3)
xp, yp, m = zip(a, b, c) tries to unpack that series of four tuples into three variables. This does not fit and a ValueError results.
for xp, yp, m in zip(a, b, c) unpacks one tuple (ax, bx, cx) at a time into xp, yp and m.
Despite my confusion (I’m not alone as a Python beginner), zip() is always working the same. The difference is what gets unpacked: an entire sequence or one iteration of a sequence. zip(a, b, c) always generates a sequence of tuples (ax, bx, cx).
When unpacking in a for loop, one iteration of the sequence—a tuple—gets unpacked:
xp, yp, m = (ax, bx, cx)
When unpacking outside a for loop, the entire sequence gets unpacked:
xp, yp, m, n = ((a0, b0, c0), (a1, b1, c1), (a2, b2, c2), (a3, b3, c3))
Understanding the Python Zip() Method (Part 1)
Posted by Mark on May 31, 2022 at 06:44 | Last modified: March 28, 2022 17:39As promised at the end of my last post, I’ve done some digging with some extremely helpful people at Python.org. Today I will work to wrap up loose ends mainly by discussing the Python zip() method.
My first burning question (Part 8) asks why L42 plots a line whereas L45 plots a point. The best answer I received says that matplotlib draws lines between points. If you give it X points then it will draw (X – 1) lines connecting those points. I was pretty much correct in realizing L45 receives one point at a time and therefore draws (1 – 1) = 0 lines.
To understand how L45 gets points, I need to better comprehend the zip() method. Zip() returns an iterator. Elements may then be unpacked via looping or through assignment.
Let’s look at the following examples to study the looping approach.
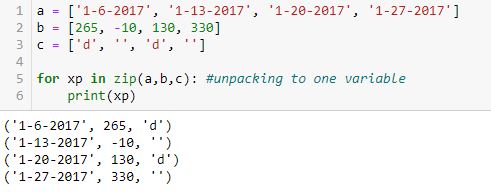
Unpacking to one variable (xp) outputs a tuple with each loop:
Unpacking to two variables (xp, yp) does not work:
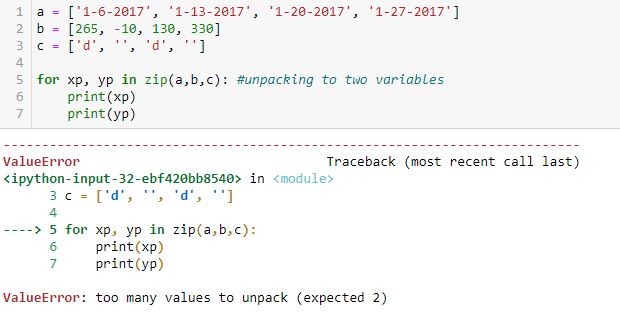
“Too many values to unpack” is confusing to me. If there are too many values to unpack for two variables, then why are there not too many to unpack for one? Perhaps the first example should be conceptualized as one sequence with four tuples. If so, then can’t this be conceptualized as one sequence with two tuples unpacked through two loops each?
Looping over the iterator with three variables yields this:
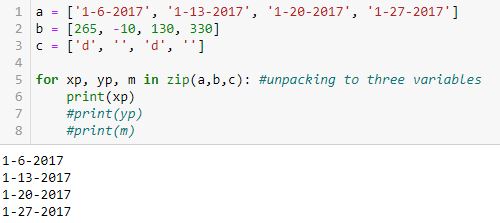
To better illustrate how the value from a gets assigned to xp, the value from b gets assigned to yp, and the value from c gets assigned to m, here is the same example with all variables printed:
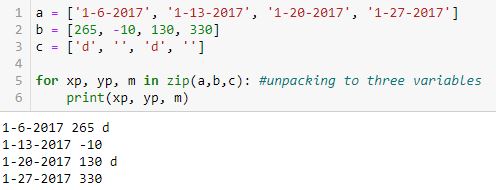
Unlike the top example, these are not tuples as no parentheses appear. Each line is just three values with spaces in between.
Looping over the iterator with four variables does not work:
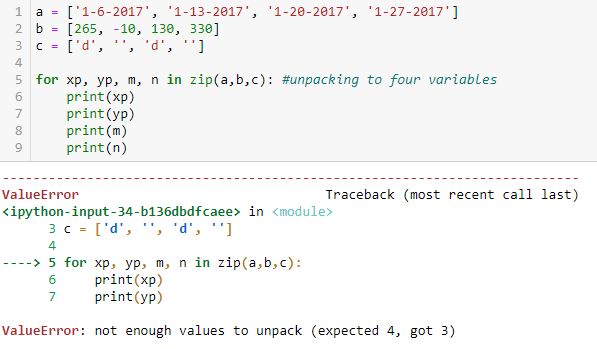
I understand why four were expected (xp, yp, m, n) and as shown in the previous example, only three lists are available to be unpacked up to a maximum of four times.
Next time, I will continue with examples of element unpacking through assignment.
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 8)
Posted by Mark on May 26, 2022 at 06:44 | Last modified: March 26, 2022 11:24Getting back to the objectives laid out here, I completed #1 in Part 4, #2-3 in Part 5, and #5 in Part 6. I will resume with objective #4: randomly select five Fridays as trade entries.
This line is pretty straightforward:

Finally, this snippet allows me to conquer objective #6:
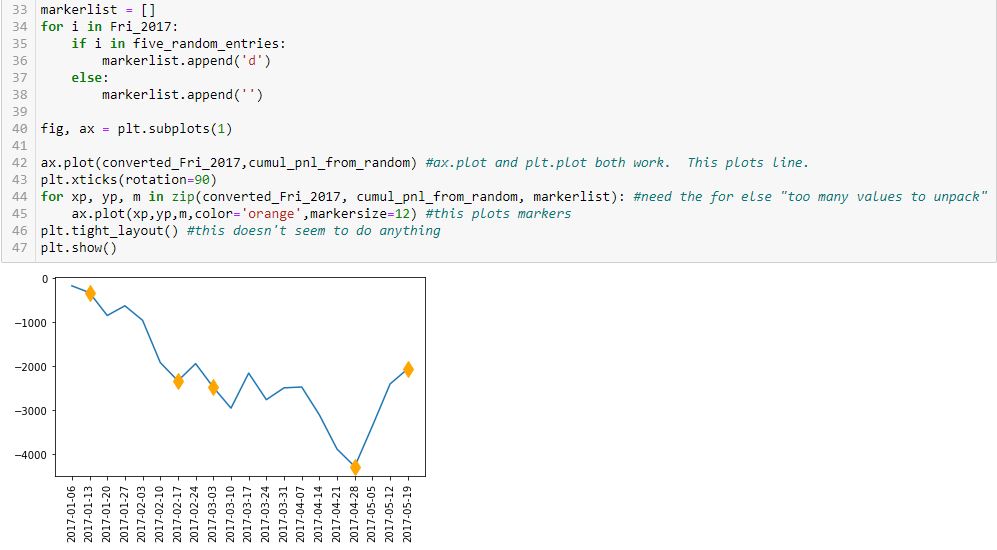
This is actually somewhat complex code for a beginner like me. I will go over a few points.
First, note that I have simplified the graph from two subplots to just one. The reason for including two subplots earlier was only to compare tick labels on the x-axis.
Second, look at the syntax of L45. The arguments are x-values, y-values, marker code, color, and markersize. L42 is an abbreviated version with just the first two arguments. L45 plots the markers while L42 plots the line. How does this work?
In L42, the arguments are datatype list.
In L45, the datatype is more complicated. The first three arguments of L45 are generated in L44 from a zip function. From W3Schools.com:
> The zip() function returns a zip object, which is an iterator of tuples where
> the first item in each passed iterator is paired together, and then the second
> item in each passed iterator are paired together etc.
The zip function itself produces a zip object. Trying to directly unpack the object into variables does not work:
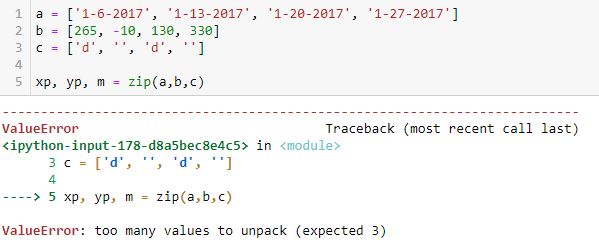
I’m still trying to understand what the “too many values” are. I would expect to get a list of (xp, yp, m) tuples from this.
As it turns out, I can get such a list with the list constructor:

Like the list constructor, the for loop is an iterator that goes over the iterable until nothing is left. Each time, it unpacks three values from the zip object: one from each list. These then get presented to L45 as the x-value, y-value, and marker code. This plots a set of points showing up as diamond markers or blank instead of a continuous line because each time three separate values are presented rather than two lists being presented at once? It’s hard for me to articulate this, which suggests that I don’t fully understand it yet.
Next time, I will do a bit more digging in order to explain this better.
In the meantime, mission accomplished for all six objectives!
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 7)
Posted by Mark on May 24, 2022 at 07:10 | Last modified: March 24, 2022 11:17I will pick up today by discussing why the x-axis labels are different for the lower subplots presented in Part 6.
To clarify some terminology, I have been saying “x-axis labels,” which I think is adequately descriptive and perhaps even correct. In different online forums, I have seen mentions of “tick labels” and “tick locations.” The 1st and 22nd of each month are tick locations on a date axis. The tick labels are what get printed at those locations. For dates on a date axis, tick locations and tick labels are identical.
The best answer I received to the original question says that matplotlib (MPL) is probably doing with dates what it does with numbers: calculating evenly-sized intervals to fit the plot (based on first and last values). He reports tick locations at the 1st and 15th of each month, though, which makes more sense as “evenly-sized.” The 21 days followed by 7-10 days I get at the 1st and 22nd of each month are lopsided. Although I still lack explanation for the latter, I did find this SO post showing the same thing (no explanation given there, either).
With regard to this line:
> converted_Fri_2017 = [d.strftime(‘%Y-%m-%d’) for d in Fri_2017] #list comprehension
Values lose meaning when converted to strings. MPL spaces strings evenly without regard to any numeric or date value.
String conversion works in this instance because tick locations = tick labels, but other cases could present problems. One such case would be non-fixed-interval trade entry dates. Another example would be a longer time horizon where too many tick labels may render the x-axis illegible. If left as dates (or datetimes: both worked the same for me) then MPL could potentially scale accordingly (see first sentence of paragraph #3, above), but converting to strings robs MPL of this opportunity.
Much functionality remains with regard to ax.xaxis.set_ticks(), ax.set_xlim(), ax.set_xticks(), ax.set_xticklabels(), ax.tick_params(), plt.setp(), AutoDateLocator, ax.xaxis.set_major_locator(MultipleLocator()) from Part 3, etc. The list goes on, and solutions are varied based on version. That is to say they may have worked when posted, but if subsequent versions have been released (especially with previous functionality deprecated), those solutions may no longer be suitable.
I do not plan to write an encyclopedia of all the available functionality. I will resort to picking and choosing based on any particular needs I have at a given time.
Categories: Python | Comments (0) | Permalink