Backtester Development (Part 6)
Posted by Mark on November 29, 2022 at 07:26 | Last modified: June 22, 2022 08:36Today I will continue discussion of logic for my revamped backtesting program.
The ‘find_spread’ control branch involves one of four paths:
- If DTE > 200 then continue.
- Elif dte_list empty, strike price multiple of 25, and strike price > underlying price by < 26, then store current_date and append option data to respective lists. At the end, the program will select two options for the spread based on available DTE. Since the iteration cannot go in reverse, potentially relevant data must be stored when encountered.
- Elif DTE matches previously-stored DTE then continue (implied is that the lists are no longer empty).
- Elif current_date still matches, then insert option data to beginning of respective lists (implied is that DTE has changed).
- Else update current_date and proceed with spread selection since iteration of all options from previous date is complete.
Motivation for requiring 25-point spreads relates to the fact that 5- and 10-point strikes were not available many years ago when option trading volume was much lower.* Even today, 25-point strikes are regarded as having the most volume and best liquidity. If true (this would be exceedingly difficult to test and may require huge amounts of capital to attain large sample sizes of live trades), then this criterion makes good sense.
Requiring 25-point spreads is not without controversy, however. If I include a penalty for slippage regardless of strike-price multiple, then I probably do not need the 25-point limitation. I think a bigger problem is nonuniform strike density, which I discussed in the fourth paragraph here.
Spread selection proceeds as a nested for loop over dte_list, which now has DTE values of matched strike-price options from the same historical date across increasingly farther-out expirations:
- First list position with value > (30 x mte) is the target short option; all related option data corresponding to this list position are now encoded as such.
- Iterate over remainder of dte_list to match first index position with value greater than S_dte + (27 x width)** as target long option; all related option data corresponding to this list position are now encoded as such.
These lists are my solution to the problem of dynamic variables described in Part 4. Rather than initializing multiple sets of variables to hold unnecessary data, data is stored in lists with each element corresponding to a particular DTE option. Once the proper DTEs are determined, corresponding values are then assigned to the only set of pre-initialized variables.
I will continue next time with the ‘update_long’ control branch.
*—2017 – 2021 option volume is shown here.
**—I am using 27 rather than 28 in case of a Friday holiday.
Generator Expressions and Iterators in Python
Posted by Mark on November 23, 2022 at 06:33 | Last modified: June 2, 2022 14:08After doing some further research, I have learned that my previous explanation of initializing multiple variables as empty lists was not very Pythonic. I want to correct some of that today.
The following is a generator expression:
( [] for i in range(3) )
The expression will generate three empty lists. Parentheses are needed around generator expressions like brackets are needed around list comprehensions:

A generator is a function that returns an object also known as an iterator.
An iterator is an object that contains a countable number of values. An iterator may be iterated over one value at a time until all values have been exhausted. Trying to iterate further will then raise a StopIteration exception (i.e. error or traceback).
A generator expression is like a list comprehension except the latter produces the entire list while the former produces one item at a time. A generator expression has “lazy execution” (producing items only when asked for), which makes it more memory efficient than a list comprehension.
Although the end result is to initialize three variables as empty lists, Pythonically speaking this is doing something else:
list_a, list_b, list_c = ( [] for i in range(3) )
The right side is an object containing three items: [], [], and []. The left side unpacks that object into three respective variables. I went into detail about unpacking with regard to the zip() method in these two posts.
Last time, I may have described things as if something magical was going on. This is not magic. The parentheses on the right represent a generator object and the commas on the left are to unpack it.
With regard to my previous discussion about making sure to use commas rather than equals signs, the latter…
a = b = c = (1, 2, 3)
…is basically doing:
c = (1, 2, 3)
b = c
a = b
b and c both get assigned (1, 2, 3).
With regard to the generator expression from above, this…
a = b = c = ( [] for i in range(3) )
…is basically doing:
c = ( [] for i in range(3) )
b = c
a = b
Because c cannot be assigned three different lists from the generator, Python assigns the generator to the variable a (and b):
<generator object <genexpr> at 0x0000019F45352200>
Lists, tuples, dictionaries, and strings are all iterable objects that have an iter() method used to return values. For example:
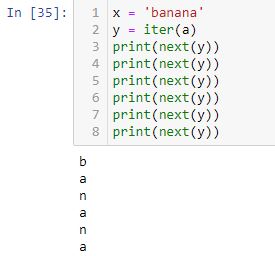
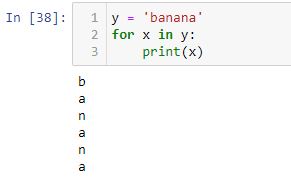
A for loop creates an iterator object, executes the next() method for each loop, and automatically stops at the end leaving us worry-free with regard to any potential [StopIteration] error:
Backtester Development (Part 5)
Posted by Mark on November 21, 2022 at 06:54 | Last modified: June 22, 2022 08:36I am extremely happy to say that since this post, I have revamped the Python code into what seems to be a properly working backtester! Today I will begin to review the logic.
While not easy, the process of dropping an existing framework into a slightly altered skeleton was not as difficult as once feared. When I first ran the revised program on a Wednesday afternoon, I wondered how many hours the debug process would take. I imagined it taking days! Previous experience had shown program fixes to not fix and when they do, to be followed by other things in need of fixing. Total debug time ended up being six hours. I had bugs, but I was able to seek and destroy.
One of my biggest struggles was organizing the variables. This literally made my head spin and kept me paralyzed for a good 60 minutes. I still don’t have a good solution except to say time working with the program breeds familiarity. I would still like to include all variables in a function and just call the function to reset and manage. That may not be practical. What I now have for variables is much different than the original key shown here. At some point, I should probably update that index.
For variable initiation and reset, I was able to condense code length by zeroing out multiple variables in a single line:
> var_a = var_b = var_c = var_d = 0
This is legit.
It took me a couple hours, however, to realize this is not:
> list_a = list_b = list_c = list_d = []
While the labels are different, each actually points to the same exact list. Changing any of them will result in a change to all, which was a real mess. A proper way to initiate multiple variables as separate lists is:
> list_a, list_b, list_c, list_d = ( [] for i in range(4) )
Precision is very important, too. The following does not yield the same result:
> list_a = list_b = list_c = list_d = ( [] for i in range(4) )
Instead of all pointing to an empty list, which is not even I wanted, done this way they all point to a generator object.
The first two paragraphs of Part 4 explain why I needed to revamp the program with regard to inconsistent DTE selection, etc. I will now proceed to describe the restructuring in words.
The basic backtesting approach remains as described in the third paragraph here. It will become evident why I was able to reduce the number of control branches to ‘find_spread,’ ‘update_long,’ and ‘update_short.’ The wait_until_next_day loop remains at the top albeit with more limited application in the current version (14).
I will continue next time.
Categories: Python | Comments (0) | PermalinkBacktester Development (Part 4)
Posted by Mark on November 15, 2022 at 06:54 | Last modified: June 22, 2022 08:36Despite my best efforts described near the end of this post and the beginning of that, the DTE combinations I was getting from the short and long legs were not what I wanted. Another mitigating factor is that depending on the cycle, options may not be available in the 120-150 DTE range. Today I will discuss what I have done to revamp the logic.
One thing I found is despite check_second, sometimes I actually needed to check a third. This made me realize I may not know exactly how many I need to check, which suggests a need for dynamically-created variables.
I’ve run up against this issue a number of times so it’s worth trying to describe a more general case and look for a solution.
Suppose I have a large data file and I don’t know how often a pattern will repeat. Each time it occurs, though, I need to capture details and later evaluate to select which one I’ll need.
What is the best way to name variables in this case?
One approach would be to define as many or more sets than I’ll ever need. For example:
> dte0 = dte1 = dte2 = dte3 = … = dte50 = 0
> row_num1 = row_num2 = row_num3 = … = row_num50 = 0
That seems like a pain.
I’d rather define and initialize the variables with a loop like:
> variable_set = [‘dte’+ str(i) for i in range(50)]
> print(variable_set)
Now I’ve got the variable names in a list… could I then initialize them as a loop?
This doesn’t work:
> for i in len(variable_set):
> int(variable_set[i]) = 0
>
> print(variable_set)
Even if that did work, I might have just changed the list to all zeros, which destroys variable names I might otherwise be able to use later in the program. I don’t know how to keep the strings as variable names for later use.
I think the solution is to use a list or dictionary and add values as needed. I can’t address particular values by unique names, but the logic in the program can dictate what values to retrieve by index/slicing and where to insert/delete the same way.
Here’s what I know:
- Short option should have at least 60 DTE.
- Long option should be next month out (for now).
- If I can identify the short option first then the long option will come easy.
- Iterating down the file means going from longer-term to short-term options, which makes this more complex.
The new solution is to encode any necessary data for options 200 DTE or lower at the proper strike price and put them in lists (e.g. dte_list, orig_price_list, orig_delta list, etc.).
Each time DTE changes, as long as historical date remains the same I will encode new data for the proper strike price. Instead of appending values to the end of lists, I will insert at the beginning.
The time to identify the spread is once historical date changes. dte_list then includes DTE of all available options on that historical date in ascending order. I can then iterate through the dte_list from beginning to end. If the value > 60 then I have found my short option and the long option will be next (for width = 1). I can then assign the appropriate values from each list to specific variable names like those listed in the key.
Categories: Python | Comments (0) | PermalinkBacktester Development (Part 3)
Posted by Mark on November 7, 2022 at 07:07 | Last modified: June 22, 2022 08:36In moving forward to eliminate the lower bound, I encountered a bug described at the end of Part 2. Today I want to finish discussing my debugging effort.
I tried all kinds of things during the next three hours. I can’t remember the exact order of what I tried or even the results of everything I did.
The bug occurred before the dataframe was printed to .csv file, which prevented me from viewing in Excel. I was able to display in JN, and that helped immensely. This revealed a long option with 28 DTE at trade inception. Of course that’s going to be a problem because it means the short option would be 0 DTE and missing upon subsequent update. I later noticed many missing short options, which I never understood.
Before looking at the dataframe, I added lines in the program to print different things as a way to track footprints. I needed to better understand what branches the program traveled through. In order to see the log file, I had to enter in JN:
> strike_file.close()
Because the ValueError occurred before the program completed, the results file remained open in Python. Closing it manually with this line made viewing the log file easier. After studying the log file and making changes, I learned to close the log file to avoid an error upon subsequently running the program again (PermissionError: [Errno 13] Permission denied).
Printing out different variables helped to determine where the bug arose and what steps the program took to get there. The list of variables I looked at grew long:
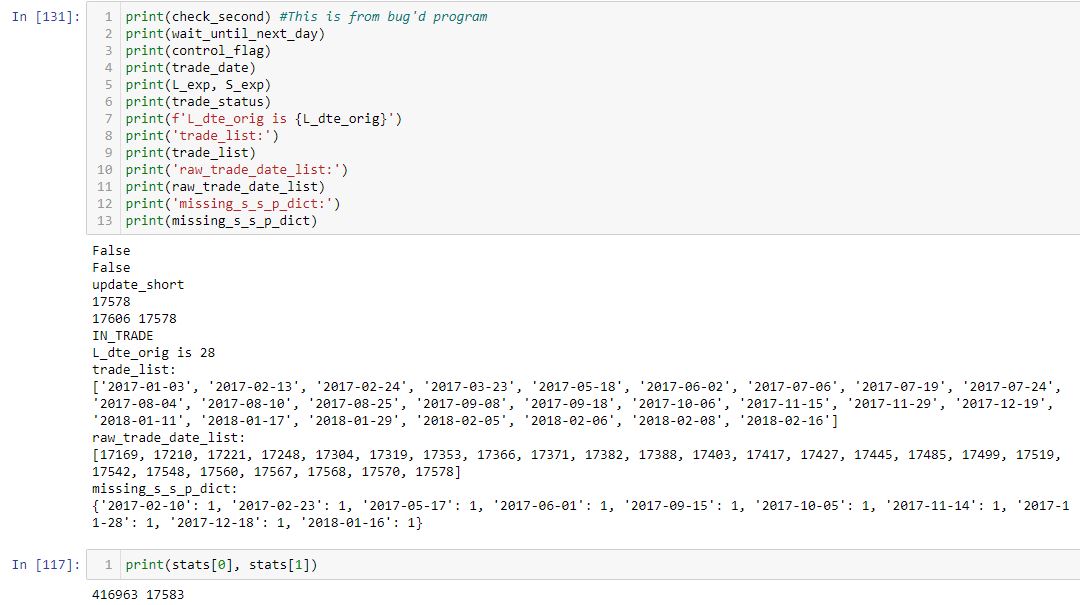
I even had to create some new variables to better interpret the old ones. raw_trade_date_list is one example because the data file—something I studied to understand on what row the program stopped due to error—shows the raw date rather than a more familiar format (see end of this post for explanation).
In many places, I inserted counters to determine how many times the program executed particular branches. This line proved particularly useful because it creates a detailed log of variables upon every iteration:
![]()
My debugging effort had many fits and starts because I would find something that seemed like a smoking gun only to make changes and see the bug remain. I became saddled with contradictory information. For example, assignment to current_date meant the program executed one branch while so-and-so flag True meant the program couldn’t have executed said branch.
I eventually noticed an instance of == when it should have been = . This led me to do a search for equals signs and verify every single one of over 350 in the code. This revealed:
- L142: control_flag == ‘find_long’ #NEEDS TO BE SINGLE = NOT ==
- L183: wait_until_next_day == True #NEEDS TO BE SINGLE = NOT ==
- L265: control_flag == ‘find_long’ #NEEDS TO BE SINGLE = NOT ==
- L266: wait_until_next_day == True #NEEDS TO BE SINGLE = NOT ==
See a pattern here? Clearly I need to improve with regard to usage of = versus == .
With these all fixed, the program runs as expected even without the lower bound.
Mission [finally] accomplished!
Categories: Python | Comments (0) | PermalinkBacktester Development (Part 2)
Posted by Mark on November 1, 2022 at 07:24 | Last modified: June 22, 2022 08:36I resume today with my detailed approach to check_second, which I provided at the end of Part 1.
In case you had trouble following all that, I concur because it’s a mess! check_second increases the find_long branch from 17 to 45 lines. In the process, I encountered a bug that took over two hours to identify.*
I also had great difficulty in keeping track of indentation:
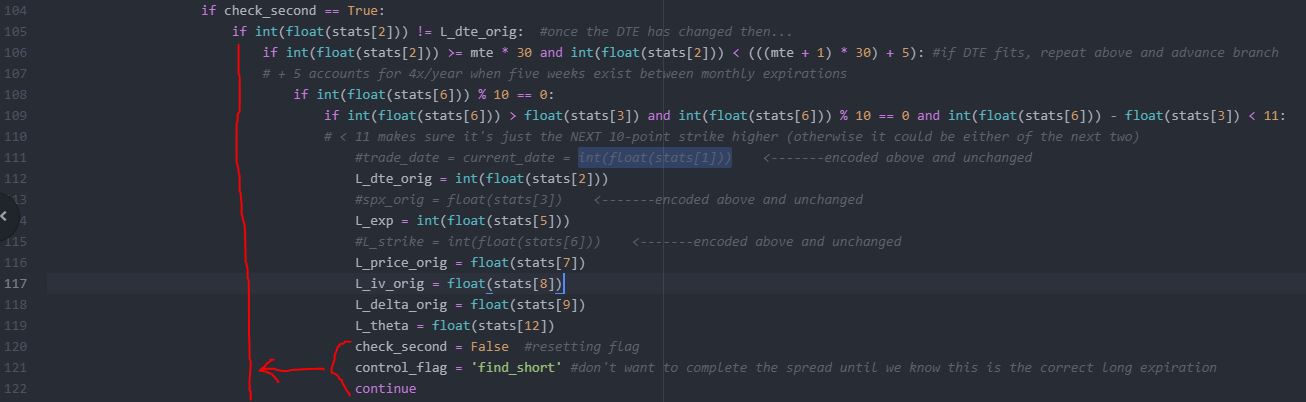
Getting the indentation wrong can screw up a program something fierce. I really need to think carefully about what’s going to happen where depending on how the conditional criteria evaluate.
Even getting the indentation correct, I am not entirely happy with the solution. I feel it’s sloppy Python, but I may not know any better at this point. The elapsed time is about three seconds longer, but I feel more confident that nothing will slip through the cracks. Perhaps a couple user-defined functions would make the nested ifs more readable.
Starting an ELSE with the same indentation whenever I begin an if statement might also help the effort. This will allow me to more easily see the proper indentation up front even if I don’t have it filled in yet. When there is nothing to do in the ELSE branch, I can always use PASS. All this is to make the code more readable, which I’m guessing would be advised by PEP 8 (Python style guide), and to decrease the risk of sloppy mistakes.
To that end, my next steps were to eliminate the redundant 10-multiple truth tests and to make sure every if has a corresponding ELSE statement. In most cases for this program, the ELSE block simply gets CONTINUE to move to the next iteration (row of data file). I am encouraged to say no bugs were encountered at this stage, which added 10 lines and included quite a bit of code manipulation aided by the Atom editor folding feature (see footnote here).
Maybe I can do right in Python after all! I also feel much better about the code with things seemingly better organized.
This confidence boost was very short-lived, however, as my next step to eliminate the lower bound (see fifth paragraph here for a refresher) resulted in the previous day’s check_second bug profile all over again:
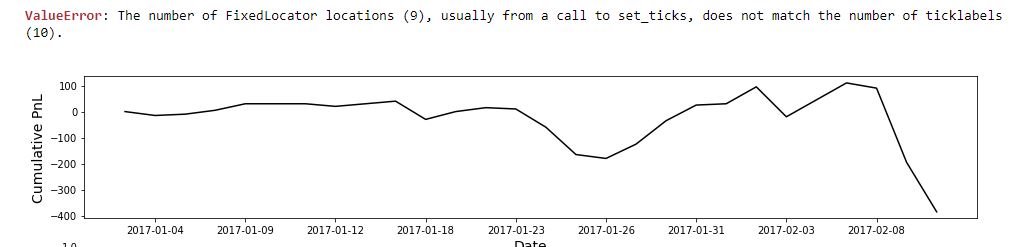
I will discuss this more next time.
*—Incidentally, the bug was in (2) because at the bottom of find_long, I assigned find_short to control_flag.
The whole idea of check_second is to hold off on taking steps to completing the spread (find_short) until
verifying the first qualifying DTE to be the only (else I want the shorter DTE).
Backtester Development (Part 1)
Posted by Mark on October 24, 2022 at 06:40 | Last modified: June 22, 2022 08:35This mini-series will be a chronicle of backtester development activities. Because so many things are a Python learning experience for me, I think it’s worth documenting them for later review.
I want to start by revisiting the problem I was having with data type conversion. I noted ignorance as to why the problem occurs. My partner filled me in:
> I think this is an excel issue. Do a right click on the file and use the “open
> with” option. Use Notepad. You will see that everything is displayed as float…
> When you open either file with excel, excel creates what looks like an integer.
In other words, this is not actually a problem. Excel makes things look nice, which in this case created an unintentional headache. Having to reformat data from a commercialized vendor source to serve my own purpose should not be surprising.
In the post linked above, I also presented some additional lines to record program duration in a log file. I couldn’t understand why the output data separated by commas was not printing to separate cells in the Excel .csv.
The explanation is the difference between the following two lines:

The commas in L305 are visible only to the Python program. In order to be visible to the application displaying the .csv file, I need to include quotation marks around the commas as if I were printing them (L307).
I enclosed the entire program in a while loop with a new variable timing_count in order to have the program run three times and log multiple elapsed times.
I then assigned current_date in find_long and reset the variable as part of the else block in L77. These were suggestions from Part 11. The program output appears unchanged. Run duration appears consistent and relatively unchanged (as best as I can tell when comparing two sets of three elapsed times each).
The next step is to add the check_second flag (discussed in Part 5), which ended up as a total mess because subsequent debugging took over two hours to seek out a “stupid mistake” (grade-school math terminology) I made in the process.
To refresh your memory especially with regard to the DTE criterion, see second paragraph of Part 6.
My approach to the check_second flag is as follows:
- The previous find_long block is split in two: check_second == False and ELSE (implies check_second == True).
- False includes a nested if statement that checks DTE criterion (ELSE CONTINUE), 10-multiple criterion, then strike price and 10-multiple (redundant) criteria followed by complete variable assignment including flipping check_second to True.
- True (ELSE block) includes a nested if statement that checks for a change in DTE (ELSE CONTINUE), DTE criterion, 10-multiple criterion, then strike price and 10-multiple (redundant) criteria followed by partial variable assignment (SPX price and strike price already assigned), resetting of check_second, assigning find_short to control_flag, and CONTINUE.
- The DTE criterion of True has ELSE block that includes: check_second reset, control_flag = find_short, and CONTINUE.
I will resume next time.
Categories: Python | Comments (0) | PermalinkData Type Conversions with the Automated Backtester
Posted by Mark on October 18, 2022 at 06:45 | Last modified: June 22, 2022 08:36I’ve struggled mightily trying to figure out how to handle types for the option data. I think the current solution may be as good as any and today I’m going to discuss how I got to this point.
The data file is .csv with the following [skipping position zero] fields:
- Date (e.g. 17169)
- DTE (e.g. 1081)
- Stock Price (e.g. 2257.83)
- Option Symbol (e.g. SPX 191220P02025000)
- Expiration (e.g. 18250)
- Strike (e.g. 2025)
- Mean Price (e.g. 203.2)
- IV (e.g. 0.209406)
- Delta (e.g. -0.30844)
- Vega (e.g. 13.1856)
- Gamma (e.g. 0.000417)
- Theta (e.g. -0.12758)
For now, I need the following fields as integers (floats for the decimal portion): 1, 2, 5, 6 (3, 7, 8, 9, 12).
Iterating over the first line of data in the file (skipping the header) with L59 (seen here) yields:

Every field I need as an integer comes up with a .0 at the end. When I try to convert to integer with int(), I get a traceback:
> ValueError: invalid literal for int() with base 10: ‘17169.0’.
I can use int(float())) every time I need to encode data from these columns. I do this 21 times in the program. It may seem like an a lot of unnecessary conversion, but I don’t want to see those trailing zeros in the results file.
If I understood why this happens in the first place, then I might be able to nip it in the bud.
Here’s a short code that works:
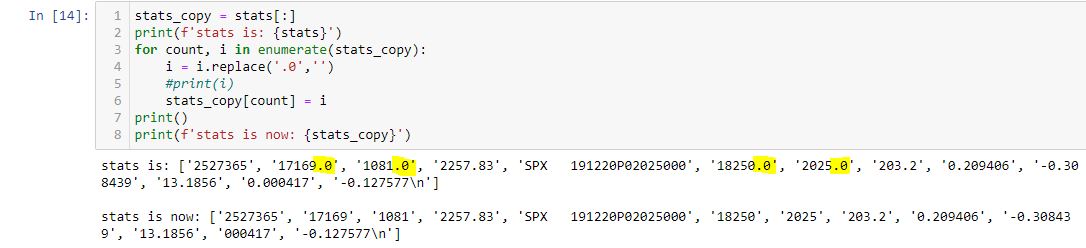
Note that each trailing zero (highlighted) is eliminated. This seems like a lot of preprocessing. The fields remain as strings (note the single quotes) and I still have to convert them to integers.
Is all this faster than 21 instances of int(float())?
I mentioned timers a couple times in this post discussing backtester logic. The following is one approach:
import time
start_time = time.time()
elapsed_time_log = open(r”C:\path\timelog.csv”,”a”)
——————-BODY OF PROGRAM——————-
now = datetime.now()
dt_string = now.strftime(“%m/%d/%Y %H:%M:%S”)
end_time = time.time()
elapsed_time = end_time – start_time
comment = ‘v.9′
print(dt_string,’ ‘, elapsed_time,’ ‘, comment, file=elapsed_time_log)
elapsed_time_log.close()
This code snippet appends a line to a .csv file with time and date, elapsed time, and a comment describing any particular details I specify about the current version. This will give me an idea how different tweaks affect program duration.
As a final note, the code screenshot shown above does not work if L1 reads stats_copy = stats because the original list then changes. This gave me fits, and is probably something every Python beginner encounters at least once.
What’s the problem?
With stats_copy = stats, I don’t actually get two lists. The assignment copies the reference to the list rather than the actual list itself. As a result, both stats_copy and stats refer to the same list after the assignment. Changing the copy therefore changes the original as well.
Aside from the slicing implemented in L1, these methods should also work:
- stats_copy = stats.copy()
- stats_copy = list(stats)
-
Categories: Python | Comments (0) | Permalink
Backtester Logic (Part 11)
Posted by Mark on October 10, 2022 at 06:45 | Last modified: June 22, 2022 08:35Moving on through the roadmap presented at the end of Part 9, let’s press forward with trade_status.
trade_status operates as a column in btstats to indicate trade progress and as a control flag to direct program flow.
You may have noticed the former by looking closely at the dataframe code snippet from Part 10. In the results file, this describes each line as ‘INCEPTION’, ‘IN_TRADE’, ‘WINNER’, or ‘LOSER’ (also noted in key).
As a control flag, trade_status is best understood with regard to the four branches of program flow (i.e. control_flag). The variable gets initiated as ‘INCEPTION’. This persists until the end of the find_short branch when it gets assigned ‘IN_TRADE’. At this point, the program no longer has to follow entry guidlines but rather match existing options (see third paragraph of Part 2). Once the whole spread has been updated at the end of update_short, the program can evaluate exit criteria to determine if trade_status needs to be assigned ‘WINNER’ or ‘LOSER’. In either of those cases, the trade is over and:
- Variable reset can occur.
- ‘INCEPTION’ gets assigned to trade_status.
- find_long gets assigned to control_flag.
- wait_until_next_day is set to True.
One variable not reset is current_date. This is needed in L65 (see Part 2) along with wait_until_next_day. For completeness, I should probably reset current_date as part of that else block (L68) and assign it once again as part of find_short or in the find_long branch with trade_date in L75.
With regard to exit logic, I have the following after variables are calculated and/or assigned in update_short:

The only exit criteria now programmed are those for max loss and profit target, but this must be expanded. At the very least, I need to exit at a predetermined/customizable DTE or when the short option expires. This may be done by expanding the if-elif block. If the time stop is hit and trade is up (down) money then it’s a ‘WINNER’ (‘LOSER’).
I will also add logic to track overall performance. I can store PnL and DIT for winning and losing trades in separate lists and run calculations. Just above this, I can check for MAE/MFE and store those in lists for later plotting or processing. I can also use btstats. Ultimately, I’d like to calculate statistics as discussed in this blog mini-series. I will take one step at a time.
I conclude with a quick note about data encoding. Following the code snippet shown in Part 1, I have:
![]()
That imports each option quote into a list—any aspect of which can then be accessed or manipulated by proper slicing.
That ends my review of the logic behind a rudimentary, automated backtester. My next steps are to modify the program as discussed, make sure everything works, continue with further development, and to start with the backtesting itself.
As always, stay tuned to this channel for future progress reports!
Categories: Python | Comments (0) | PermalinkBacktester Logic (Part 10)
Posted by Mark on October 4, 2022 at 07:11 | Last modified: June 22, 2022 08:35Today I will continue by following the road map laid out at the end of Part 9.
I will begin with the results file. I have been using Jupyter Notebook for development and I can plot some graphs there, but I want to print detailed results to a .csv file. I am currently generating one such file that shows every day of every trade. Eventually, I want to generate a second file that shows overall trade statistics.
The results file gets opened at the beginning and closed at the end of the program with these lines:
![]()
![]()
In an earlier version, I then printed to this file as part of the find_short and update_short branches with lines like this:

While I find the syntax interesting, I realized these are pretty much just string operations that won’t help me to calculate higher-level trade statistics. Numpy will be much better for that, which is why I decided to compile the results into btstats (dataframe). Done that way, I can still get the results file in the end with this line:
![]()
The dataframe is created near the beginning of the program:

Most of the columns have corresponding variables (see key) and/or are derived through simple arithmetic on those variables.
Now, instead of printing to the results file in two out of the four branches I add a list to the dataframe as a new row:

I searched the internet to find this solution here. One nice thing about Python is that I can find solutions online for most things I’m looking to accomplish. That doesn’t mean I understand how they work, though. For example, I understand df.loc[] to accept labels rather than integer locations (df.iloc[], which I have also learned cannot expand the size of a dataframe). len(btstats.index) is an integer so I’m not sure why it works. This is a big reason why I still consider myself a pupil in Python.
L127 is an example of variable reset (discussed in Part 9). This is what I want to do for every variable once it has served its purpose to make sure I don’t accidentally use old data for current calculations (e.g. next historical date).
Let’s take a closer look at L121:
![]()
The data file includes a date field as “number of days since Jan 1, 1970” format. Multiplying that by 86400 seconds/day yields number of seconds since midnight [UTC], Jan 1, 1970, which is the proper format for the datetime module’s UTC timestamp. I can now use the .strftime() method and ‘%b’ to get the first three letters as an abbreviated month name. Being much more readable than a nonsensical 5-digit integer, this is what I want to see in the results file.
The light at the end of the tunnel is getting brighter!
Categories: Python | Comments (0) | Permalink