Backtester Logic (Part 1)
Posted by Mark on August 1, 2022 at 07:26 | Last modified: June 22, 2022 08:34Now that I have gone over the modules and variables used by the backtester, I will discuss processing of data files.
My partner (second paragraph here) has done some preprocessing by removing rows pertaining to calls, weekly options, deepest ITM and deepest OTM puts, and by removing other unused columns. Each row is a quote for one option with greeks and IV. I tend to forget that I am not looking at complete data files.
As the backtester scans down rows, option quotes are processed from chronologically ordered dates. Each date is organized from highest to lowest DTE, and each DTE is organized from lowest to highest strike price.
My partner had given some thought to building a database but decided to stick with the .csv files. Although I did take some DataCamp mini-courses on databases and SQL, I feel this is mostly over my head. I trust his judgment.
I believe the program will be most efficient (fastest) if it collects all necessary data from each row in a single pass. I can imagine other approaches that would require multiple runs through the data files (or portions therein). As backtester development progresses (e.g. overlapping positions), I will probably have to give this further thought.
The first row and column of the .csv file are not used. The backtester iterates down the rows and encodes data from respective columns when necessary. The first column is never called. Dealing with the first row—a string header with no numbers—requires an explicit bypass. It could raise an exception since the program evaluates numbers. The bypass is accomplished by the first_bar flag (initially set to True) and an outer loop condition:
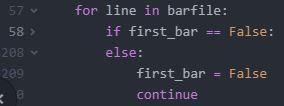
The first iteration will set the flag to False and skip everything between L58 and L208. The bulk of the program will then apply to the second iteration and beyond.
To maximize efficiency, the backtester should encode as little as possible because most rows are extraneous. Backtesting a time spread strategy that is always in the market with nonoverlapping positions requires monitoring 2 options/day * ~252 trading days/year = 504 rows. My 2015 data file has ~120,000 rows, which means just over 0.4% of the rows are needed.
I will therefore avoid encoding option price, IV, and greeks data unless all criteria are met to identify needed rows.
A row is needed if it has a target strike price and expiration month on a particular date but once again, in the interest of efficiency the backtester need not encode three elements for every row. It can first encode and evaluate the date, then encode and evaluate the expiration month, and finally encode and evaluate the strike price. Each piece of information need be encoded only if the previous is a match. Nested loops seem like a natural fit.
I will continue next time.